1. 평가지표
1-1. 지도학습 - 분류모델 평가 지표
| 실제 답 | |||
| True | False | ||
| 예측 결과 | Positive | True Positive | False Positive |
| Negative | False Nagative | True Negative | |
오차행렬(혼동행렬, Confusion Matrix)
- True Positive(TP) : 실제 True인 답을 True라고 예측(정답)
- False Positive(FP) : 실제 False인 답을 True라고 예측(오답)
- False Negative(FN) : 실제 True인 답을 False라고 예측(오답)
- True Negative(TN) : 실제 False인 답을 False라고 예측(정답)
1) 오차행렬(Confusion Matrix)
훈련을 통한 예측 성능을 측정하기 위해 예측 값과 실제 값을 비교하기 위한 표이다.
2) 정확도(Accuracy)
실제 데이터와 예측 데이터를 비교하여 같은지를 판단한다. 정확도는 모델의 전체적인 분류 성능을 나타낸다. 높은 정확도는 모델이 입력 데이터를 정확하게 분류하는 능력을 의미하지만 클래스 불균형이 있는 데이터 셋에서 잘못된 평가 결과를 줄 수 있다. 이 경우에는 정밀도(Precision), 재현율(Recall), F1 점수(F1-score)등 다른 지표를 함께 고려해야한다.
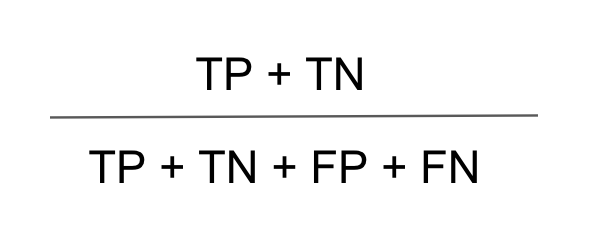
3) 정밀도(Precision)
Positive로 예측한 대상 중에 실제로 Positive인 값의 비율이다. 정밀도는 클래스간의 불균형이 있는 데이터셋에서 유용하게 사용될 수 있다. 예를 들어, 암 진단 시나리오에서는 암 환자를 정확하게 판단하는 것이 중요하며, 정밀도가 높은 모델이 선호된다.
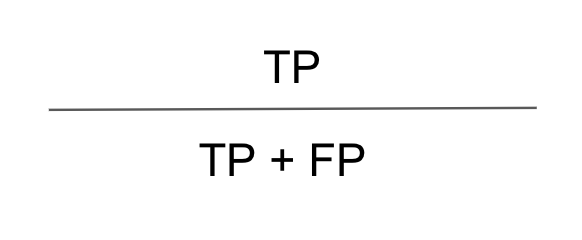
4) 재현율(Recall, 민감도)
실제 Positive인 대상 중에 Positive로 정확하게 예측한 값의 비율이다. 높은 재현율은 모델이 실제 양성인 데이터를 놓치지 않고 잘 찾아냈다는 것을 의미한다. 재현율은 클래스간의 불균형이 있는 데이터셋에서 유용하게 사용될 수 있다.

5) F1-score
정밀도와 재현율을 결합한 조화평균 지표로 값이 클수록 모형이 정확하다고 판단할 수 있다.
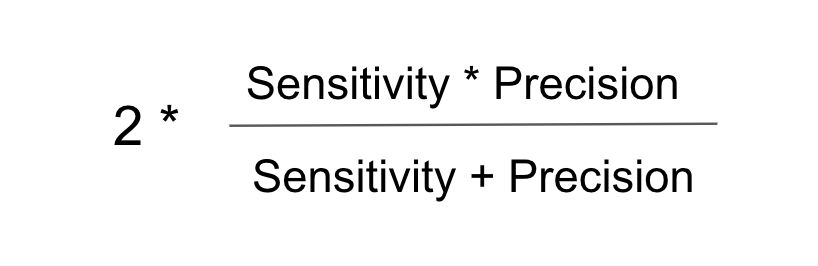
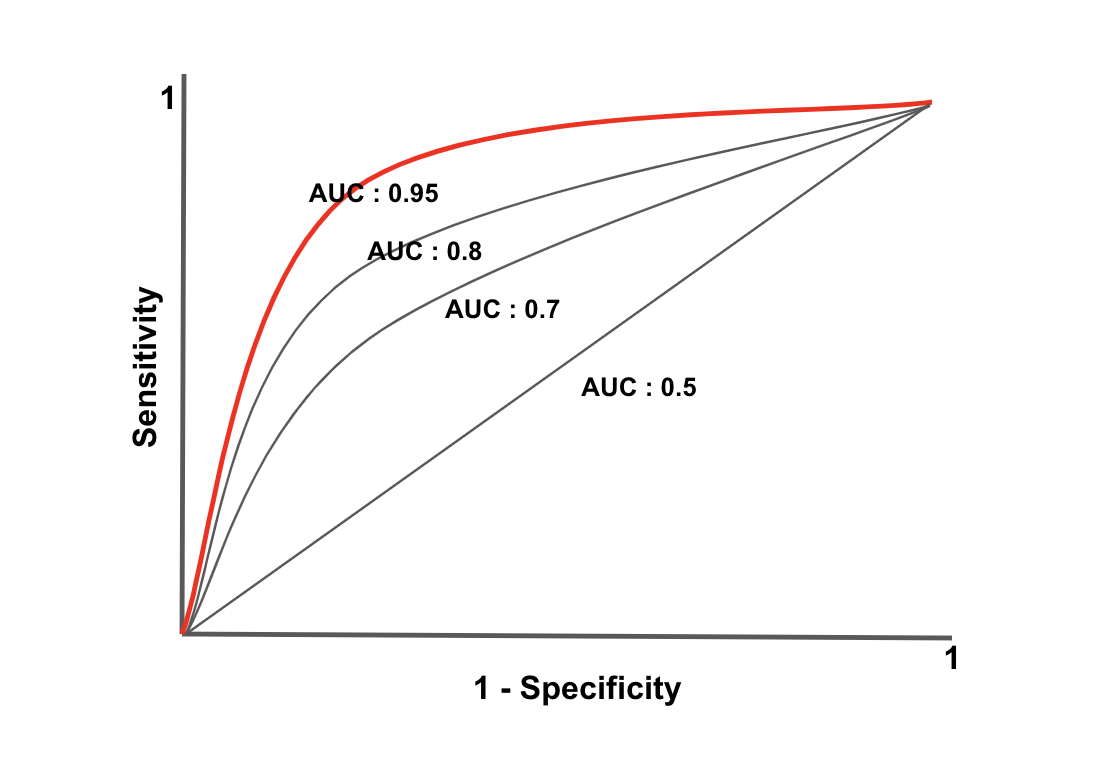
6) ROC(Receiver Operating Characteristic) 곡선
FPR(False Positive Rate, 1-특이도)이 변할 때 TPR(True Positive Rate, 민감도)이 어떻게 변화하는지를 나타내는 곡선이다.
- X축에 FPR, y축에 TPR을 나타내며, 임계값을 1~0 범주 이내 값으로 조정하면서 FPR에 따른 TPR을 계산하면서 곡선을 그린다.
- ROC 곡선의 모양은 분류 모델의 성능을 나타낸다. ROC 곡선으 왼쪽 상단 모서리에 가까울수록 좋은 성능을 가지는 모델임을 나타낸다.(높은 재현율과 높은 특이도를 동시에 갖는 모델을 의미)
- ROC 곡선이 45도 직선에 가까울수록 성능이 낮은 모델을 나타낸다.(재현율과 특이도가 비슷한 수준으로 유지되는 모델을 의미한다.)
7) AUC(Area Under Curve)
평가모델의 ROC 곡선의 하단 면적이다.
- AUC 갑은 0에서 1 사이의 값을 가지며, 분류 모델의 성능을 종합적으로 평가하는 지표이다.
- AUC가 1에 가까울수록 분류 모델의 성능이 우수하다고 할 수 있다.
| 이진 분류 모델의 성능이 다음과 같을 때, 정밀도, 재현율, F1 Score를 계산해보면 True Positives (TP) : 50 False Positives (FP) : 10 False Negatives(FN) : 25 True Negatives(TN) : 90 정밀도(Precision) = TP / (TP + FP) = 50 / (50 + 10) = 50 / 60 = 0.8333 재현율(Recall) = TP/(TP + FN) = 50 / (50 + 25) = 50 / 75 = 0.6667 F1 Score = 2 * (precision * Recall) / (Precision + Recall) = 2 * (0.8333 * 0.6667) / (0.8333 + 0.6667) ≈ 0.7407 |
1-2. 지도학습 - 회귀모델 평가 지표
회귀 평가를 위한 지표는 실제 값과 회귀 예측값의 차이를 기반으로 성능 지표들을 수립, 활용한다.
1) SSE(Sum Squared Error)
실제값과 예측값의 차이를 제고하여 더한 값이다.
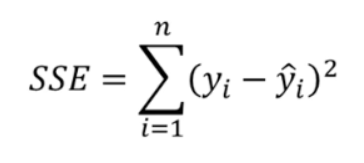
2) MSE(Mean Squared Error)
실제값과 예측값의 차이의 제곱에 대한 평균을 취한 값으로 평균 제곱 오차라고도 한다.

3) RMSE(Root Mean Squared Error)
MSE에 루트를 취한 값으로 평균제곱근 오차라고도 한다.
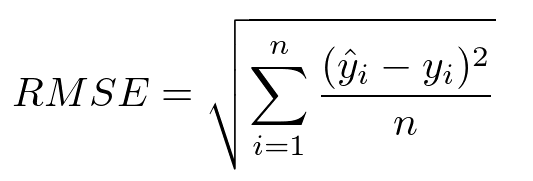
4) MAE(Mean Absolute Error)
실제값과 예측값의 차이의 절대값을 합한 평균값이다.
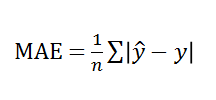
5) 결정계수 R²
회귀모형이 실제값에 대해 얼마나 잘 적합하는지에 대한 비율이다.

6) Adjusted R² (수저오딘 결정계수)
다변량 회귀 분석에서 독립변수가 많아질수록 결정계수가 높아지는데 이를 보완한 결정계수로 표본크기(n)와 독립변수의 개수(p)를 추가적으로 고려하여 분모에 위치시킴으로써 결정 계수 값의 증가도를 보정한다.

7) AIC(Akaike Information Criterion)
최대 우도에 독립변수의 개수에 대한 손실(penalty)분을 반영하는 목적으로 모형과 데이터의 확률 분포 차이를 측정하는 것으로 AIC값이 낮을수록 모형의 적합도가 높아진다.
AIC = -2logL + 2K
1-3. 비지도학습 - 군집분석 평가 지표
- 비지도학습은 지도학습과 달리 실측자료에 라벨링이 없으므로 모델에 대한 성능평가가 어렵다.
- 군집분석에 한해 다음과 같은 성능 평가 지표를 참고한다.
1) 실루엣 계수(Silhouette Coefficient)
a(i)는 i번째 개체와 같은 군집에 속한 요소들 간 거리들의 평균이며 b(i)는 i번째 개체가 속한 군집과 가장 가까운 이웃군집을 선택 계산한 값으로 a(i)가 0이면 하나의 군집에서 모든 개체들이 붙어있는 경우로 실루엣 지표가 0.5보다 클 시 적절한 군집 모델로 볼수 있다.

2. 분석모형 진단
2-1. 정규성 가정
정규성 가정은 통계적 검정, 회귀 분석 등 분석을 진행하기 전에 데이터가 정규분포를 따르는지를 검정하는 것으로 데이터 자체의 정규성을 확인하는 과정이다.
1) 중심극한정리(Central Limit Theorem)
- 동일한 확률분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규분포에 가까워진다는 이론으로 이때 표본 분포의 평균은 모집단의 모평균과 동일하며 표준편차는 모집단의 모표준편차를 표본 크기의 제곱근으로 나눈것과 같다.
2) 정규성 검정 종류
- 샤피로 윌크 검정(Shapiro-wilk Test) : 표본 수(n)가 2000개 미만인 데이터 셋에 적합하다.
- 콜모고로프 스미르노프 검점(Kolmogorove-Smirnov Test) : 표본 수(n)가 2000개 초과인 데이터 셋에 적합하다.
- Q-Q플롯(Quantile-Quantile Plot) : 데이터 셋이 정규분포를 따르는지 판단하는 시각적 분석 방법으로 표본 수(n)가 소규모일 경우 적합하다.
데이터셋이 정규분포를 따른다는 귀무가설을 기각하고 대립가설이 채택된다면(p < 0.01 또는 p = 0.05) 해당 데이터셋은 정규분포를 따르지 않음으로 증명된다.
2-2. 잔차진단(오차진단)
회귀분석에서 독립변수와 종속변수의 관계를 결정하는 최적의 회귀선은 실측치와 예측치의 차이인 잔차를 가장 작게 해주는 선으로 잔차의 합은 0이며 잔차는 추세, 특정 패턴을 가지고 있지 않다.
1) 잔차의 정규성 진단
- 신뢰구간 추정과 가설검증을 정확하게 하기 위해 Q-Q Plot과 같은 시각화 도표를 통해 정규분포와 잔차의 분포를 비교한다.
2) 잔차의 등분산성 진단
- 잔차의 분산이 특정 패턴이 없이 순서와 무관하게 일정한지 등분산성을 진단한다.
3) 잔차의 독립성 진단
- 잔차의 독립성이 자기상관(auto correlation)의 여부를 판단하는 것이며 시점 순서대로 그래프를 그리거나 더빈-왓슨 검점(Durbin-Waston Test)으로 패턴이 없다면 독립성을 충족한다고 할 수 있다. 만일 독립성이 위배가 된다면 시계열 분석(Time Series)을 통해 회귀분석을 진행해야 한다.
'빅데이터분석기사 > 필기' 카테고리의 다른 글
| (4과목) 빅데이터 결과 해석 ③ (0) | 2024.03.28 |
|---|---|
| (4과목) 빅데이터 결과 해석 ② (0) | 2024.03.28 |
| (2과목) 빅데이터 탐색 ② (1) | 2024.03.21 |
| (2과목) 빅데이터 탐색 ① (0) | 2024.03.19 |
| (1과목) 빅데이터 분석 기획 ③ (0) | 2024.03.18 |

댓글