1. 데이터 내에 내제된 변수
1-1. 데이터 관련 정의
1) 데이터(Data) : 이론을 세우는 기초가 되는 사실 또는 자료를 지칭하여 컴퓨터와 연관되어 프로그램을 운용할 수 있는 형태로 기호화 수치화한 자료를 말한다.
2) 단위(Unit) : 관찰되는 항목 또는 대상을 지칭한다.
3) 관측값(Observation) : 각 조사단위별 기록정보 또는 특성을 말한다.
4) 변수(Variable) : 각 단위에서 측정된 특성 결과이다.
5) 원자료(Raw Data) : 표본에서 조사된 최초의 자료를 이야기한다.
1-2. 데이터의 종류
1) 단변량자료(Unvariate Data) : 자료의 특성을 대표하는 특성 변수가 하나인 자료이다.
2) 다변량자료(Multivariate Data) : 자료의 특성을 대표하는 특성 변수가 두 가지 이상인 자료이다.
3) 질적자료(Qualitative Data) : 정성적 또는 범주형 자료라고도 하며 자료를 범주의 형태로 분류한다. 분류의 편의상 부여된 수치의 크기자체에는 의미를 부여하지 않는 자료이며 명목자료, 서열자료 등이 질적 자료로 분류된다.
| 질적자료 | 설명 |
| 명목자료 (Nominal Data) |
측정대상이 범주나 종류에 대해 구분되어지는 것을 수치 또는 기호로 분류되는 자료이다. ex) 전화번호상의 국번 지역번호(명목자료 처리시 사용가능한 연산자는 ≠, =) |
| 서열자료 (Ordinal Data) |
명목자료와 비슷하나 수치나 기호가 서열을 나타내는 자료이다. ex) 기록경기의 순위 등 일반적인 순위를 나타내는 대부분의 자료를 지칭(자료 처리시 사용가능 연산자는 ≠, =, ≤, ≥) |
4)수치자료(Quantitative Data) : 정량적 또는 연속형 자료라고 한다. 숫자의 크기에 의미를 부여할 수 있는 자료를 나타내며 구간자료, 비율자료가 여기에 속한다.
| 수치자료 | 설명 |
| 구간자료 (Interval Data) |
명목자료, 서열자료의 의미를 포함하면서 숫자로 표현된 변수에 대해서 변수간의 관계가 산술적인 의미를 가지는 자료이다. ex) 온도(비율로 의미가 부여될 수 있는 자료가 아니며 사용연산자는 ≠, =, ≤, ≥ ,+,-) |
| 비율자료 (Ratio Data) |
명목자료, 서열자료, 구간자료의 의미를 다 가지는 자료로서 수치화된 변수에 비율의 개념을 도입할 수 있는 자료이다 ex) 무게(사용연산자는 ≠, =, ≤, ≥, +, -, ×, ÷) |
5) 시계열자료(Time Series Data) : 일정한 시간 간격 동안에 수집된, 시간개념이 포함되어있는 자료이다.
ex) 일별 주식 가격
6) 횡적자료(Cross Section Data) : 횡단면자료라고도 하며 특정 단일 시점에서 여러 대상으로부터 수집된 자료이다. 즉 한 개의 시점에서 여러 대상으로부터 취합하는 자료를 말한다.
7) 종적자료 (Longitudinal Data) : 시계열자료와 횡적 자료의 결합으로 여러 개체를 여러시점에서 수집한 자료이다.
데이터의 종류는 앞의 내용에서 변수들의 집합인 자료의 종류와 그 특성을 동일하게 가지므로 데이터의 종류에 따라서 적용방법론이 다양하게 변화할 수 있다.
2. 데이터 결측값 처리
데이터 분석에서 결측치(결측값, Missing Data)는 데이터가 없음을 의미한다.
1) 결측치를 임의로 제거 시 : 분석 데이터의 직접손실로 분석에 필요한 유의수준 데이터 수집에 실패할 가능성이 발생한다.
2) 결측치를 임의로 대체 시 : 데이터의 편향(bias)이 발생하여 분석 결과의 신뢰성 저하 가능성이 있다.
결측치에대한 처리는 임의 제거 대체의 방법을 사용함에 있어 상기의 문제를 피하는 데이터에 기반한 방법으로 처리해야한다.
2-1. 결측 데이터의 종류
1) 완전 무작위 결측(MCAR : Missing Completely At Random) : 어떤 변수상에서 결측 데이터가 관측된 혹은 관측되지 않는 다른 변수와 아무런 연관이 없는 경우이다.
2) 무작위 결측(MAR : Missing At Random) : 변수상의 결측 데이터가 관측된 다른 변수와 연관되어 있지만 그 자체가 비관측값들과는 연관되지 않은 경우이다.
3) 비 무작위 결측(NMAR : Not Missing At Random) : 어떤 변수의 결측 데이터가 완전 무작위 결측(MCAR) 또는 무작위 결측(MAR)이 아닌 결측데이터로 정의하는 즉, 결측변수값이 결측여부(이유)와 관련이 있는 경우이다.
| 나이대별(X), 성별(Y)과 체중(Z) 분석에 대한 모델링을 가정해보면 - X,Y,Z와 관계없이 Z가 없는 경우 : 데이터 누락(응답 없음) -> 완전 무작위 결측 (MCAR) - 여성(Y)은 체중 공개를 꺼려 하는 경향 : Z가 누락될 가능성이 Y에만 의존 -> 무작위 결측(MAR) - 젊은(X) 여성(Y)의 경우 체중 공개를 꺼리는 경우가 더 높음 -> 무작위 결측 (MAR) - 무거운(가벼운) 사람들은 체중 공개 가능성이 적음 : Z가 누락될 가능성이 Z값 자체에 관찰되지 않는 값에 달려 있음 -> 비 무작위 결측 (NMAR) |
2-2. 결측값 유형의 분석
- 결측치의 처리를 위해서 실제 데이터셋에서 결측치가 어떤 유형으로 분류되는지 분석하고 분석된 겨로가에 따라서 결측치 처리 방법의 선택이 필요하다.
- 일반적으로 결측 무응답을 가진 자료를 분석할 때는 완전 무작위 결측(MCAR)하에 처리한다. 즉, 불완전한 자료는 무시하고 완전히 관측된 자료만을 표준적 분석을 시행한다. 그러나 이런 결측치가 존재하는 데이터를 이용한 분석은 다음 세가지 고려사항이 발생하는데 효율성(efficiency), 자료처리의 복잡성, 편향(bias) 문제이다.
1) 단순 대치법(Simple Imputation)
기본적으로 결측치에 대하여 MCAR 또는 MAR로 판단하고 이에대한 처리를 하는 방법이다.
- 완전 분석(Completes Analysis) : 불완전 자료는 완전하게 무시하고 분석을 수행한다. 분석의 용이성을 보장하나 효율성 상실성과 통계적 추론의 타당성에 문제 발생 가능성이 있다.
- 평균 대치법(Mean Inputation) : 관측 또는 실험으로 얻어진 데이터의 평균으로 결측치를 대치해서 사용한다. 평균에 의한 대치는 효율성의 향상 측면에서 장점이 있으나 통계량의 표준오차가 과소 추정되는 단점이 있다. 비조건부 평균 대치법이라고도 한다.
- 회귀 대치법(Regression Imputation) : 회귀분석에 의한 예측치로 결측치를 대치하는 방법으로 조건부 평균 대치법이라고도 한다.
- 단순확률 대치법(Single Stochastic Imputation) : 평균 대치법에서 추정량 표준오차의 과소 추정을 보완하는 대치법으로 Hot-deck 방법이라고도 한다. 확률추출에 의해서 전체 데이터 중 무작위로 대치하는 방법이다.
- 최근접 대치법(Nearest-Neighbor Imputation) : 전체 표본을 몇개의 대체군으로 분류하여 각 층에서의 응답자료를 순서대로 정리한 후 결측값바로 이전의 응답을 결측치로 대치한다. 응답값이 여러번 사용될 가능성이 단점이다.
2) 다중 대치법(Multiple Imputation)
단순 대치법을 복수로 시행하여 통계적 효율성 및 일치성 문제를 보완하기 위하여 만들어진 방법이다. 복수 개(n개)의 단순대치를 통해 n개의 새로운 자료를 만들어 분석을 시행하고 시행결과 얻어진 통계량에 대해 통계량 및 분산 결합을 통해 통합하는 과정이다.
- 1단계 - 대치단계(Imputation Step) : 복수의 대치에 의한 결측을 대치한 데이터를 생성한다.
- 2단계 - 분석단계(Analysis Step) : 복수 개의 데이터 셋에 대한 분석을 시행한다.
- 3단계 - 결합단계(Combination Step) : 복수 개의 분석 결과에 대한 통계적 결합을 통해 결과를 도출한다.
3. 데이터 이상값 처리
이상치(이상값, Outlier)란 데이터의 전처리 과정에 발생 가능한 문제로 정상의 범주(데이터의 전체적 패턴)에서 벗어난 값을 의미한다. 데이터의 수집과정에서 오류가 발생할 수도 있기 때문에 이상치가 포함될 수 있다. 오류가 아니더라도 굉장히 극단적인 값의 발생으로 인한 이상치가 존재할 수도 있다.
이상치는 앞선 결측치와 마찬가지로 부석결과의 왜곡이 발생할 수 있으므로 처리하는 작업이 필요하다.
3-1. 이상치의 탐지
종속변수가 단변량(Univariate)인지 다변량(Multivariate)인지 데이터의 분포를 고려하여 모수적(Parametric) 또는 비모수적(Non-parametric)인지에 따라 다양한 방법으로 고려해야 한다.
1) 시각화(visualization)를 통한 방법(비모수적, 단변량(2변량)의 경우)
① 상자 수염 그림(Box Plot, 상자 그림)
- 데이터의 분포를 한 눈에 볼 수 있게 시각화하여 이상치 등을 탐지할 수 있는 시각화 도구이다. 데이터의 최솟값, 최댓값, 중앙값, 1사분위수(Q1), 3사분위수(Q3)등을 표현한다.
② 줄기-잎 그림(Stem and Leaf Diagram)
- 줄기-잎 그림은 주로 작은 데이터셋에 적합하여 각 데이터 포인트를 숫자의 일부인 줄기와 그 줄기에 해당하는 값들의 리스트인 잎으로 분리하여 나타낸다. 이를 통해 데이터의 분포와 이상치를 확인할 수 있다.
③ 산점도 그림(Scatter Plot)
- 두 변수로 이루어진 데이터를 2차원 평면 상에 점으로 표현하는 시각화 방법으로, 데이터 포인트들이 그래프 상에서 너무 멀리 떨어져 있는 값을 이상치로 판단한다.
2) Z-score 방법(모수적 단변량 또느 저변량의 경우) *정규분포
① Z-score는 데이터 포인트가 평균으로부터 얼마나 떨어져 있는지를 표준편차의 단위로 나타내는 통계적 지표이다.
② Z-score를 이용한 이상치 탐지 방법
- 먼저 데이터를 정규화하여 평균이 0이고 표준편차가 1인 표준정규분포로 변환한다. 이를 위해 각 데이터 포인트에서 평균을 빼고, 표준편차로 나누어 준다
- 정규화된 데이터 포인트(x)의 Z-score를 계산한다.
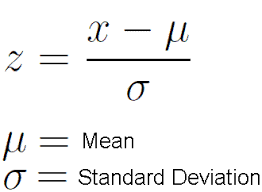
- 통상적으로 threshold는 1σ 사이(전체의 68.27%), 2σ 사이(전체의 95.45%), 3σ 사이(전체의 99.73%)등을 사용한다.
③ Z-score를 이용한 이상치 탐지 방법은 데이터가 정규분포를 따른다고 가정할 때 효과적으로 작동할 수 있으며, 비정규분포를 따르는 경우에는 잘못된 결과를 도출할 수 있으므로 주의가 필요하다. 또한, 이상치 탐지는 데이터의 특성과 분석 목적에 따라 적절한 임계값 설정이 필요하며, 추가적인 검토와 판단이 필요할 수 있다.
3) 밀도기반 클러스터링 방법(DBSCAN : Density Based Spatial Clustering of Appli-cation with Noise)
비모수적 다변량의 경우 군집간의 밀도를 이용하여 특정 거리 내의 데이터수가 지정 개수 이상이면 군집으로 정의하는 방법이다. 정의된 군집에서 먼거리에 있는 데이터는 이상치로 간주한다.
4) 고립 의사나무 방법(Isolation Forest)
데이터가 다른 데이터들과 얼마나 분리되어 있는지를 측정하여 이상치를 탐지한다. 알고리즘의 매개변수 설정과 이상치 판단 기준의 임계값 설정에 따라 결과가 달라질 수 있다.
- 고립 의사결정나무의 동작 과정
① 데이터 포인트 분할 : 먼저 데이터를 분할하여 의사결정나무를 생성한다. 데이터를 분할할 때는 이상치를 찾기 위해 특정기준을 사용한다.
② 분할 기준 설정 : 분할 기준은 데이터의 특성에 따라 정해진다. 예를 들어, 데이터의 특성 값이 특정 임계값보다 큰 경우와 작은 경우로 분할할 수 있다.
③ 분할된 데이터 영역 계산 : 각 분할된 영역에서의 데이터 밀도를 계산한다. 이를 통해 데이터가 다른 데이터들과 얼마나 분리되어 있는지를 측정할 수 있다.
④ 이상치 탐지 : 데이터의 분리 정도를 기준으로 이상치를 탐지한다. 일반적으로 밀도가 낮은 영역에 위치한 데이터들이 이상치로 간주된다.
⑤ 의사결정나무 생성 : 데이터의 분할과 이상치 탐지를 반복하여 의사결정나무를 생성한다. 이상치를 제외한 정상 데이터들은 나무의 잎 노드에 할당된다.
4. 변수 선택
통계적 분석 결과의 신뢰성을 위해 기본적으로 데이터와 이를 특정 짓는 변수는 많으면 좋다. 하지만 분석 모형을 구성하고 사용하는 데 지속적으로 필요 이상의 많은 데이터를 요구할 수 있다.
1) 회귀분석의 사례
회귀모형에 의한 분석의 경우 최종 결과를 도출해 내기 위해서 사용된 독립 변수가 m개이고 이를 통해서 얻어진 설명력이 R^2=89%라고 했을때, m보다 작은 n개 만을 사용시 동일한 설명력이 나온다면 변수의 효율적 선택의 필요성이 증가한다.
2) 변수별 모형의 분류
① 전체 모형(FM : Full Model) : 모든 독립변수를 사용한 모형으로 정의한다.
② 축소 모형(RM : Refuced Model) : 전체 모형에서 사용된 변수의 개수를 줄여서 얻은 모형이다.
③ 영 모형(NM : Null Model) : 독립변수가 하나도 없는 모형을 의미한다.
3) 변수의 선택 방법
① 전진 선택법(Foward Selection)
- 영 모형에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의 절댓값이 가장 큰 변수를 분석모형에 포함시키는 것을 말한다.
- 부분 F검정(F test)을 통해 유의성 검정을 시행하여, 유의한 경우는 가장 큰 F 통계량을 가지는 모형을 선택하고 유의하지 않은 경우는 변수 선택 없이 과정을 중단한다.
- 한번 추가된 변수는 제거하지 않는 것이 원칙이다.
② 후진 선택법(Backward Selection), 후진 소거법(Backward Elimination)
- 전체 모델에서 시작, 모든 독립변수 중 종속 변수와 단순상관계수의 절댓값이 가장 작은 변수를 분석모형에서 제외시킨다.
- 부분 F검정을 통해 유의성 검증을 시행, 유의하지 않은 경우는 변수를 제거하고 유의한 경우는 변수제거 없이 과정을 중단한다.
- 한번 제거된 변수는 추가하지 않는다.
③ 단계적 선택법(Stepwise Selection)
- 전진 선택법과 후진 선택법의 보완 방법이다.
- 전진 선택법을 통해 가장 유의한 변수를 모형에 포함 후 나머지 변수들에 대해 후진 선택법을 적용하여 새롭게 유의하지 않은 변수들을 제거한다.
- 제거된 변수는 다시 모형에 포함하지 않으며 유의한 설명 변수가 존재하지 않았을때까지 과정을 반복한다.
5. 차원 축소
5-1.차원 축소의 필요성
1) 복잡도의 축소 (Reduce Complexity)
데이터를 부석하는데 있어서 분석시간의 증가(시간복잡도 : Time Complexity)와 저장변수 양의 증가(공간복잡도 : Space Complexity)를 고려 시 동일한 품질을 나타낼수 있다면 효율성 측면에서 데이터 종류의 수를 줄여야한다.
2) 과적합(Overfit)의 방지
- 차원의 증가는 분석모델 파라미터의 증가 및 파라미터 간의 복잡한 관계의 증가로 분석결과의 과적합 발생가능성이 커진다. 이것은 분석 모형의 정확도(신뢰도) 저하를 발생시킬 수 있다.
- 작은 차원만으로 안정적인(robust) 결과를 도출해 낼 수 있다면 많은 차원을 다루는 것보다 효율적이다.
3) 해석력(Interpretability)의 확보
- 차원이 작은 간단한 분석모델일수록 내부구조 이해가 용이하고 해석이 쉬워진다.
- 해석이 쉬워지면 명확한 결과 도출에 많은 도움을 줄수 있다.
4) 차원의 저주(Curse of Dimensionality)
- 데이터 분석 및 알고리즘을 통한 학습을 위해 차원이 증가하면서 학습데이터의 수가 차원의 수보다 적어져 성능이 저하되는 현상이다.
- 해결을 위해서 차원을 줄이거나 데이터의 수를 늘리는 방법을 이용해야한다.
5-2. 차원 축소의 방법
데이터 분석에 있어서 차원 축소의 필요성을 인지하고 실제적으로 차원을 축소하는데 사용될 수 있는 방법이다.
1) 요인 분석(Factor Analysis)
① 요인 분석의 개념
- 다수의 변수들 간의 관계(상관관계)를 분석하여 공통차원을 축약하는 통계분석 과정이다.
②요인분석의 목적
- 변수 축소 : 다수의 변수들의 정보손실을 억제하면서 소수의 요인(Factor)으로 축약하는 것을 말한다.
- 변수 제거 : 요인에 대한 중요도 파악이다.
- 관련된 변수들이 묶임(군집)으로써 요인 간의 상호 독립성 파악이 용이해진다.
- 타당성 평가 : 묶여지지 않는 변수의 독립성 여부를 판단한다.
- 파생변수 : 요인 점수를 이용한 새로운 변수를 생성한다. 회귀분석, 판별분석 및 군집분석 등에 이용할 수 있다.
③요인 분석의 특징
- 독립변수, 종속변수 개념이 없다. 주로 기술 통계에 의한 방법을 이용한다.
④요인 분석의 종류
- 주성분 분석, 공통요인 분석, 특이값 분해(SVD : Singular Value De-composition) 행렬, 음수미포함 행렬분해(NMF : Non-negative Matrix Factorization) 등이 있다.
- 공통요인 분석은 분석대상 변수들의 기저를 이루는 구조를 정의하기 위한 요인분석 방법으로 변수들이 가지고 있는 공통분산만을 이용하여 공통요인만 추출하는 방법이다.
2) 주성분 분석(PCA : Principal Component Analysis)
① 주성분 분석의 개념
- 분포된 데이터들의 특성을 설명할 수 있는 하나 또는 복수 개의 특징(주성분, Principal COmponent)을 찾는것을 의미한다.
- 서로 연관성이 있는 고차원 공간의 데이터를 선형 연관성이 없는 저차원(주성분)으로 변환하는 과정을 거친다(직교변환을 사용)
- 기존의 기본변수들을 새로운 변수의 세트로 변환하여 차원을 줄이되 기존 변수들의 분포특성을 최대한 보존하여 이를 통한 분석결과의 신뢰성을 확보한다.
② PCA 방법의 이해
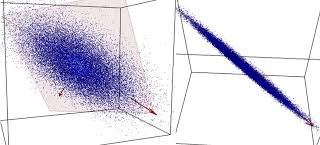
- v1의 방향과 크기, 그리고 v2의 방향과 크기를 알면 이 데이터 분포가 어떤 형태인지를 가장 단순하면서도 효과적으로 파악할 수 있다.
- PCA는 데이터 하나하나에 대한 성분을 분석하는 것이 아니라 여러데이터들이 모여 하나의 분포를 이룰 때, 이 분포의 주성분을 분석해주는 방법이라고 할수 있다.
③PCA특징
- 차원 축소에 폭 넓게 사용된다. 어떠한 사전적 분포 가정의 요구가 없다.
- 가장 큰 분산의 방향들이 주요 중심 관심으로 가정한다.
- 본래의 변수들의 선형결합으로만 고려한다.
- 차원의 축소는 본래의 변수들이 서로 상관이 있을 때만 가능하다.
- 스케일에 대한 영향이 크다. 즉 PCA 수행을 위해선 변수들 간의 스케일링이 필수다.
6. 파생변수의 생성
데이터 분석시 주어진 원데이터를 그대로 활용하기보다는 분석의 목표에 적합하게 계속해서 데이터 형태를 수정보완할 필요가 있다.
데이터 마트(Data Mart)는 데이터 웨어하우스(Data Warehouse)로부터 복제 또는 자체 수집된 데이터 모임의 중간층이지만 분석을 위한 기본단계변수가 모여지는 단계로 요약변수와 파생변수들의 모임이라고 볼 수 있다.
6-1. 파생변수
1) 사용자가 특정조건을 만족하거나 특정 함수에의해 값을 만들어 의미를 부여하는 변수로 매우 주관적일 수 있으므로 논리적 타당성을 갖출 필요가 있다.
2) 세분화 고객행동예측, 캠페인반응예측 등에 활용할 수 있다.
3) 특정 상황에만 유의미하지 않게 대표성을 나타나게 할 필요가 있다.
6-2. 요약변수
1) 수집된 정보르 분석에 맞게 종합(aggregate)한 변수이다.
2) 데이터 마트에서 가장 기본적인 변수이다.
3) 많은 분석 모델에서 공통으로 사용될 수 있어 재활용성이 높다.
7. 변수 변환
7-1. 변수변환의 개념
1) 데이터를 분석하기 좋은 형태로 바꾸는 작업을 말한다. 수학적 의미로 변환(transformation)은 기존 변수공간에서는 해결하거나 관찰할 수 없는 사실을 영역을 달리하는 것으로(변환) 해석이 용이해지거나 취급이 단순해지는 장점이 있다.
2) 데이터의 전처리 과정(Data Preprocessing) 중 하나로 간주된다.
7-2. 변수 변환의 방법
① 정규화
분석을 정확히 하려면 원래 주어진 연속형(이산형) 데이터 값을 바로 사용하기 보다는 정규화를 이용하는 경우가 타당할 수 있다.
특히, 데이터가 가진 스케일이 심하게 차이나는 경우 그 차이를 그대로 반영하기 보다는 상대적 특성이 반영된 데이터로 변환하는 것이 필요하다.
- 일반 정규화 : 수치로 된 값들을 여러 개 사용할 때 각 수치의 범위가 다르면 이를 같은 범위로 변환해서 사용하는데 이를 일반 정규화라고 한다.
- 최소-최대 정규화(Min-Max Normalization) : 데이터를 정규화 하는 가장 일반적인 방법이다.
* 모든 feature에 대해 최소값 0, 최대값 1로 그리고 다른 값들은 0과 1사이의 값으로 변환하는 것이다.
*만약 X라는 값에 대해 최소-최대 정규화를 한다면 다음과 같은 수식을 사용할 수 있다.
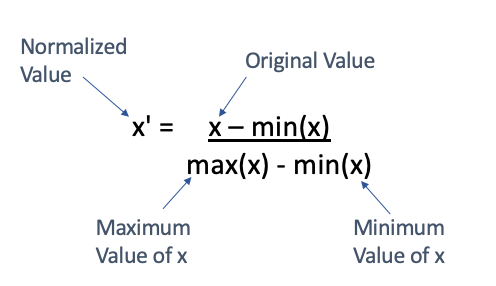
* 최소-최대 정규화의 단점으로 이상치(outlier) 영향을 많이 받는 점에 유의한다.
- Z-점수(Z-score) 정규화 : 이상치 문제를 피하는 데이터 정규화 전략이다.
* 만약 데이터의 값이 평균과 일치하면 0으로 정규화되고, 평균보다 작으면 음수, 평균보다 크면 양수로 나타난다. 이때 계산되는 음수와 양수의 크기는 데이터의 표준편차에 의해 결정된다. 그래서 만약 데이터의 표준편차가 크면(값이 넓게 퍼져있으면) 정규화되는 값이 0에 가까워진다.
* 이상치를 잘 처리하지만, 정확히 동일한 척도로 정규화된 데이터를 생성하지 않는다느 점에 유의한다.
② 로그변환(Log Transformation)
로그변환이란 어떤 수치값을 그대로 사용하지 않고 여기에 로그를 취한 값을 사용하는것을 말한다.
데이터 분석에서 로그를 취하는게 타당한 경우가 종종 있는데 먼저 로그를 취하면 그 분포가 정규 분포에 가깝게 분포하는 경우가 있다. 이런 분포를 로그 정규분포 (Log-normal Distribution)를 가진다고 한다.
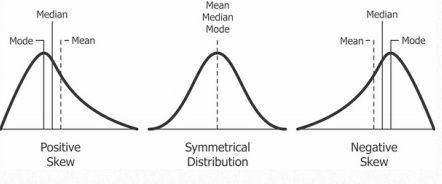
③ 분포형태별 정규분포로의 변환
모집단의 분포형태별로 사용가능한 변수변환이 다르다. 최종적으로 정규분포 형태를 지향한다.
8. 불균형 데이터 처리
어떤 데이터에서 각 클래스(주로 범주형 반응 변수)가 갖고 있는 데이터의 양에 차이가 큰 경우, 클래스 불균형이 있다고 말한다.
8-1. 불균형 데이터의 문제점
- 데이터 클래스 비율이 너무 차이가 나면(Highly - imbalanced Data) 단순히 우세한 클래스를 택하는 모형의 정확도가 높아지므로 모형의 성능판별이 어려워진다. 즉, 정확도(accuracy)가 높아도데이터 개수가 적은 클래스의 재현율(recall-rate)이 급격히 작아지는 현상이 발생할 수 있다.
8-2. 불균형 데이텅의 처리 방법
1) 가중치 균형방법(Weighted Balancing)
데이터에서 손실(loss)을 계산할 때 특정 클래스의 데이터에 더 큰 loss값을 갖도록 하는 방법이다. 즉 데이터 클래스의 균형이 필요한 경우로 각 클래스별 특정 비율로 가중치를 주어서 분석하거나 겨로가를 도출하는 것으로 저의한다.
- 고정비율 이용
* 클래스의 비율에 따라 가중치를 두는 방법이다. 예를 들면 클래스의 비율이 1:5라면 가중치를 5:1로 줌으로써 적은 샘플수를 가진 클래스를 전체손실이 동일하게 기여하도록 할 수 있다.
- 최적 비율 이용
* 분야와 최종 성능을 고려해 가중치 비율의 최적 세팅을 찾으면서 가중치를 찾아가는 방법이다.
2) 언더샘플링(Undersampling) 과 오버샘플링(Oversampling)
비대칭 데이터는 다수 클래스 데이터에서 일부만 사용하는 언더 샘플링이나 소수 클래스 데이터를 증가시키는 오버샘플링을 사용하여 데이터 비율을 맞추면 정밀도(precision)가 향상된다.
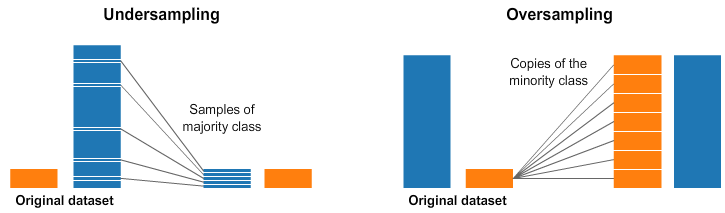
- 언더샘플링
* 언더샘플링은 대표클래스(Majority Class)의 일부만을 선택하고, 소수클래스(Minority Class)는 최대한 많은 데이터를 사용하는 방법이다. 이때 언더 샘플링된 대표클래스 데이터가 원본 데이터와 비교해 대표성이 있어야 한다.
- 오버샘플링
* 소수클래스의 복사본을 만들어, 대표클래스의 수만큼 데이터를 만들어 주는 것이다. 똑같은 데이터를 그대로 복사하는 것이기 때문에 새로운 데이터는 기존 데이터와 같은 성질을 갖게 된다.
'빅데이터분석기사 > 필기' 카테고리의 다른 글
| (4과목) 빅데이터 결과 해석 ① (0) | 2024.03.26 |
|---|---|
| (2과목) 빅데이터 탐색 ② (1) | 2024.03.21 |
| (1과목) 빅데이터 분석 기획 ③ (0) | 2024.03.18 |
| (1과목) 빅데이터 분석 기획 ② (2) | 2024.03.17 |
| (1과목) 빅데이터 분석 기획 ① (3) | 2024.03.17 |

댓글