1. 데이터 탐색의 개요
1-1. 탐색적 데이터 분석(EDA : Exploratory Data Analysis
수집한 데이터가 들어왔을 때 다양한 방법을 통해서 자료를 관찰하고 이해하는 과정을 의미하는 것으로 본격적인 데이터 분석 전에 자료를 직관적인 방법으로 통찰하는 과정이다.
1-2. 이상치의 검출
이상치가 왜 발생했는지 의미를 파악하는 것이 중요하다. 그리고 그러한 의미를 파악했으면 어떻게 대처해야할지(제거, 대체, 유지 등)를 판단한다.
1) 통계값 활용
- 적절한 요약 통계 지표(SummaryStatistic)를 사용할 수 있다.
- 데이터의 중심을 알기 위해서는 평균(mean), 중앙값(median), 최빈값(mode)을 사용할 수 있다.
- 데이터의 분산도를 알기 위해서는 범위(range), 분산(variance)을 사용할 수 있다.
- 통계지표를 이용할 때는 데이터의 특성에 주의해야한다. 예를 들어 평균에는 집합 내 모든 데이터 값이 반영되기 때문에, 이상값이 있으면 값이 영향을 받지만, 중앙값에는 가운데 위치한 값 하나가 사용되기 때문에 이상값의 존재에도 대표성이 있는 결과를 얻을 수 있다.
* 분산 : 관측값에서 산술평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한것
* 정규 분포 : 평균을 중심으로 좌우 대칭인 종 모양을 이루는 분포
* 표준정규분포 : 정규 분포 중에서 평균이 0이고 표준편차가 1인 것, 변수를 z를 쓰며 z-분포라고 줄여 부르기도 한다.
- 통계값 활용 방법
① IQR(Inter Quartile Range) 방법(사분위범위를 이용한 이상치 제거 방법)
- 전체 데이터들을 오름차순으로 정렬하고, 정확히 4등분(25%, 50%, 75%, 100%)으로 나눈다.
75% 지점의 값(75% percentile : 3사분위수)과 25% 지점(25% percentile : 1 사분위수)의 값의 차이를 IQR이라고 정의한다.
- 최대값 = 75%percentile : 3사분위수 + 1.5 × IQR
- 최소값 = 25%percentile : 1사분위수 + 1.5 × IQR
결정된 최대값보다 크거나 최소값보다 작은 값을 이상치로 간주한다.

2) 시각화 활용
시각적인 표현은 분석에 많은 도움을 준다. 시각화를 통해 주어진 데이터의 개별 속성에 어떤 지표가 적절한지 결정할 수 있다.
- 시각화 방법에는 확률밀도 함수, 히스토그램, 점플롯(dot plot), 워드 클라우드, 시계열 차트, 지도 등이 있다.
3) 머신러닝 기법 활용
- 대표적인 머신러닝 기법으로 K-means(군집분석)을 통해 이상치를 확인할 수 있다.
- 정상 데이터의 패턴을 학습하여 이사치를 검출하는 방법이 주로 사용된다.
2. 상관관계분석
2-1. 변수 간의 상관성 분석
두 변수 간의 어떤 선형적 관계를 갖고 있는지를 분석하는 방법이다. 두 변수는 서로 독립적인 관계이거나 상관된 관계일 수 있으며 이떄 두 변수간의 관계의 강도를 상관관계(correlation)라 한다.
① 단순상관분석(Simple Correlation Analysis) : 단순히 두 개의 변수가 어느정도 강한 관계에 있는가를 측정한다.
② 다중상관분석(Multiple Correlation Analysis) : 3개 이상의 변수간의 관꼐 강도를 측정한다.
- 평상 관계분석(Partial Correlation Analysis) : 다중상관분석에서 다른 변수와의 관계를 고정하고 두 변수의 관계강도를 측정하는 것을 말한다.
2-2. 상관분석의 기본가정
1) 선형성 : 두 변인 X와 Y의 관계가 직선적인지를 알아보는 것으로 이가정은 분포를 나타내는 산점도를 통하여 확인할 수 있다.
2) 동변량성(등분산성, Homoscedasticity) : X의 값에 관계없이 Y의 흩어진 정도가 같은 것을 의미한다. 반의어는 이분산성(Heteroscedasticity)이다.
- 산포가 특정 구간에 상관없이 퍼진 정도가 일정할 때 자료가 동변량성을 띤다고 얘기하며, 반대로 그 정도가 일정하지 않으면 이분산성을 보인다고 말한다.
3) 두 변인의 정규 분포성 : 두 변인의 측정치 분포가 모집단에서 모두 정규분포를 이루는 것이다.
4) 무선독립표본 : 모집단에서 표본을 뽑을때 표본대상이 확률적으로 선정된다는 것이다.
2-3. 상관분석 방법
1) 피어슨 상관계수(Pearson Correlation Coefficient 또는 Pearson`s r)
- 두 변수 X와 Y간의 선형 상관관계를 계량화한 수치이다.
- 피어슨 상관계수는 +1과 -1사이의 값을 가지며, +1은 완벽히 양의 선형 상관관계, 0은 선형 상관관계 없음, -1은 완벽한 음의 선형 상관관계를 의미한다.

2) 스피어만 상관계수(Spearman Correlation Coefficient)
- 데이터가 서열 자료인 경우, 즉 자료의 값 대신 순위를 이용하는 경우(서열 데이터)의 상관관계수로서, 데이터를 작은 것부터 차례로 순위를 매겨 서열 순서로 바꾼 뒤 순위를 이용해 상관계수를 구한다.
- 두 변수간의 연관 관계가 있는지 없는지를 밝혀 주며 자료에 이상점이 있거나 표본크기가 작을 때 유용하다.
2-4. 기초 통계량의 추출과 이해
1) 자료 분포 형태(Shape of Distribution)
① 왜도(skewness)
- 왜도는 분포의 비대칭(asymmetry) 정도를 나타내는 통계적 측도이다. 데이터 분포의 대칭성과 비대칭성을 정량화하여 평가하는 데 사용된다.
- 분포가 대칭이면 왜도는 0이다. 왼쪽으로 치우친 경우 왜도는 양수, 오른쪽으로 치우친 경우 왜도는 음수이다.
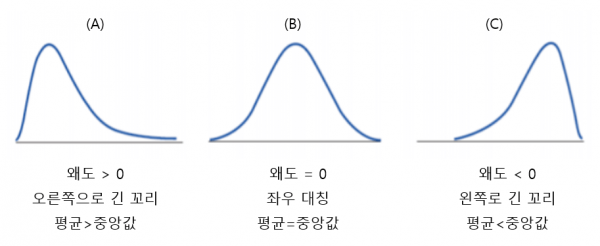
- 왜도는 분포의 모양 뿐만 아니라 이상치의 존재 여부를 파악하는데에도 도움을 줄 수 있다. 이상치는 분포의 비대칭성을 높이고, 왜도의 크기를 변화시킨다.

- 왜도의 값은 일반적으로 -3과 +3 사이의 범위에 있으며, 보통 왜도의 절대값이 1.96보다 크면 비대칭성이 있다고 판단할 수 있다. 하지만 규칙성 기준은 아니며 데이터 분포의 특성과 분석 목적에 따라 다르다
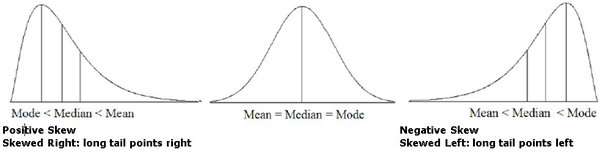
| 왜도(skewness) | 모양 | 성질 |
| 양수(Positive) | 오른쪽으로 긴꼬리 | 평균 > 중앙값 > 최빈값 |
| 0 | 좌우대칭 | 평균 = 중앙값 = 최빈값 |
| 음수(Negative) | 왼쪽으로 긴꼬리 | 평균 < 중앙값 < 최빈값 |
② 첨도(Kurtosis)
분포의 뾰족한(peakedness) 정도를 나타내는 통계적 척도이다.

3. 시각적 데이터 탐색
3-1. 통계적 시각화 도구
1) 도수분포표(Frequency Table) : 수집된 자료를 적절한 계급에 의해 분류하여 정리한 표로 질적 자료의 경우는 각 자료값(범주)에 대하여 도수나 상대도수로 표현한다.
| 상품 | 도수 | 상대도수 |
| 콘 형태 아이스크림 | 65 | 65/100=0.65 |
| 막대 형태 아이스크림 | 25 | 25/100=0.25 |
| 기타 | 10 | 10/100=0.1 |
| 합계 | 100 | 1.0 |
- 도수(Frequency) : 질적 자료의 경우 각 범주별 빈도
- 상대도수(Relative Frequency) : 도수 / 전체 자료 수
- 양적 자료의 경우는 전체 자료를 그룹화(계급구간)하고 각 그룹별 속하는 자료의 수를 계산하여 도수 및 상대도수로 표현한다.
4. 다변량 데이터 탐색
다변량 데이터 탐색은 기본적으로 변수들 간 인과관계의 규명과 분석을 하는 것이다. 변수들 간의 상관관계를 이용하여 변수를 축약하거나 개체들을 분류하고 관련된 분석방법 등을 동원하여 데이터 분석을 하는 것이다.
4-1. 종속변수와 독립변수 사이의 인과 관계
1) 다중회귀(Multiple Regression)
독립변수가 2개 이상인 회귀모형을 지칭하며 각 독립변수는 종속변수와 선형 관계에 있음을 가정한다.
- 장점
* 변수를 추가하여 분석내용의 질적 향상을 도모할 수 있다.(단순회귀분석의 단점을 극복할 수 있다.)
* 종속변수를 설명하는 독립변수가 두 개일 떄 단순회귀모형을 설정한다면 모형설정(specification)이 부정확할 뿐 아니라 종속변수에 대한 중요한 독립 변수를 누락함으로써 계수 추정량에 대해 편이(bias)를 야기 시킬 수 있다. 다중회귀분석을 통해 편이를 제거할 수 있다.
- 기본가정
* 회귀모형은 모수에 대해 선형인 모형이다.
* 오차항의 평균은 0이다.
* 오차항의 분산은 모든 관찰치에 대해 σ^2의 일정한 분산을 갖는다.
* 서로 다른 관찰치 간의 오차항은 상관이 없다.(오차항은 서로 독립이며 공분산은 0)
* 오차항의 각 독립변수 역시 독립인 관계이다.
* 오차항은 정규분포를 따르며 N(0, σ^2)이다.
- 분석 방법
* 최소자승법을 이용하여 겨로가를 도출할 수 있다.
2) 로지스틱 회귀(Logistic Regression)
영국의 통계학자인 D. R. Cox가 1958년에 제안한 확률 모델로 독립변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용된는 통계 기법이다.
- 특징
* 로지스틱 회귀의 모델은 종속변수와 독립변수 사이의 관계에 있어서 선형 모델과 차이점을 지니고 있다. 첫 번째 차이점은 이향형인 데이터에 적용하였을때 종속 변수 y의 결과가 범위[0,1]로 제한된다는 것이고 두번째 차이점은 종속변수가 이진적이기 때문에 조건부 확률 P(y | x)의 분포가 정규분포 대신 이항 분포를 따른다.
* 독립 변수는 실제 값, 이진 값, 카테고리 등 어떤 형태든 될 수 있다. 종속변수의 형태는 연속 변수(수입, 나이, 혈압)또는 이산 변수(성별, 인종)로 구분된다. 만약 특정 이산 변수값의 후보가 2개이상 존재한다면 일반적으로 해당 후보들을 임시 변수로 변환하여 로지스틱 회귀를 수행한다.
3) 분산분석(ANOVA : Analysis of Variance)
분산분석은 3개 이상의 표본들의 차이를 표본평균 간의 분산과 표본 내의 관측치간 분산을 비교하여 가설을 검정하는 것이다.
- 일원분산분석(One-Way Anova) : 단 하나의 인자에 근거하여 여러 수준으로 나누어지는 분석이다.
- 일원분산분석의 특징
* 일원분산분석은 단일용인변수(독립변수)에 의해 종속변수에 대한 평균치의 차이를 검정하는 데 이용한다.
* 일원분산분석을 위해서는 종속변수(등간 척도)와 정수값을 갖는 요인 변수가 각 하나여야하고 요인 변수가 정의되어야 한다.
4-2. 두 확률분포 간의 독립성
1) 분포의 독립성 확인
두 확률변수의 결합 확률분포를 확인하여 독립성을 판단할 수 있다. 두 변수가 상호 독립이라면, 결합 확률분포는 두 개별 변수의 확률 분포의 곱과 동일해야 한다. 즉, P(X, Y) = P(X) * P(Y)의 관계를 만족해야 한다.
2) 공분산 및 상관 계수 확인
두 확률 변수의 공분산과 상관계수를 계산하여 판단할 수 있다. 두 변수가 상호 독립이라면 공분산은 0이 되며, 상관계수도 0이 된다. 따라서, 공분산이 0이고 상관계수가 0인 경우 두 변수가 독립적이라고 할 수 있다.
3) 독립성 검정
독립성을 확인하기 위해 독립성 검정을 수행할 수 있다. 대표적인 검정 방법으로는 카이제곱 독립성 검정이 있다. 이 검정은 주어진 데이터에서 두 변수간의 독립성을 검정하는 방법으로 유의수준을 설정하여 검정 결과를 해석할 수 있다.
4-3. 변수 축약
변수들 간의 상관관계를 이용하여 변수를 줄이는 방법으로 변수유도기법이라고도 한다.
1) 주성분 분석(PCA:Principal Component Analysis)
- 다변량자료에서 존재하는 비정규성(abnormality)이나 이상치(outlier)를 발견하기 위하여 변수들의 상관관계(또는 공분산)가 존재하지 않는 새로운 변수(주성분)를 구하는 것을 지칭한다.
- 주성분 분석은 N개의 변수로부터 서로 독립인 K(N)개의 주성분을 구해 원 변수의 차원을 줄이는 방법이다.
2) 요인분석(Factor Analysis)
다수의 변수들의 상관관계를 분석하여 공통차원들을 통해 축약해 나가는 방법으로 이해하면 된다. 즉 다수의 변수들 간 정보손실을 최소화하면서 소수의 요인(Factor)으로 축약하는 것이다.
- 요인 분석의 특징
* 독립변수와 종속변수의 개념이 없다.
* 추론통계가 아닌 기술통계기법에 의해 수행할 수 있다.(상관분석 등)
- 요인 분석의 목적
* 변수 축소 : 여러 개의 관련변수가 하나의 요인으로 묶인다.
* 변수 제거 : 요인에 포함되지 않거나 포함되더라도 중요도가 낮은 변수를 찾을 수 있다.
* 변수 특성 파악 : 관련된 변수들의 묶음으로 상호 독립특성을 파악하기 용이해진다.
* 측정항목의 타당성 평가 : 그룹이 되지 않은 변수의 특성을 구분할 수 있게 된다.
* 요인점수를 통한 변수 생성 : 회귀분석, 군집분석, 판별분석 등에 적용가능한 변수를 생성할 수 있다.
3) 정준상관분석(Canonical Analysis)
두 변수집단 간의 연관성(Association)을 각 변수집단에 속한 변수들의 선형결합(Linear Combination)의 상관계수를 이용하여 분석하는 방법이다. (일반화된 상관계수)
| 스트레스하에서 심리적 상황을 나타내는 변수들과 육체적인 변수들이 어떻게 상호작용하는지에 관심이 있다면, 심리적인 것들로 간주되는 불안도, 집중력 정도 등의 변수들과 혈압, 맥박, 심전도 등과 같은 육체적 측면의 변수들을 측정하고, 이들 사이의 연관성을 보는것이 바람직할 것이다. 각 변수집단에 속하는 변수들의 선형결합은 선형결합들 사이의 상관관계가 최대가 되도록 가중값(Weight)을 결정하여 구성한다. |
- 정준변수(Canonical Variable) : 새로 만들어진 선형결합니다.
- 정준상관계수(Canonical Correlation Coefficient) : 정준변수들 사이의 상관계수이다.
두 집단에 속하는 변수들의 개수 중에서 변수의 개수가 적은 집단에 속하는 변수의 개수만큼의 정준변수가 만들어질 수 있다.
- 정준분석과 회귀분석의 차이점
* 회귀분석의 경우 하나의 반응변수를 여러 개의 설명 변수로 설명하고자 할 때, 가장 설명력이 높은 변수들의 선형결합을 찾아 이들 사이의 인과관계를 생각하는 반면에 정준분석에서는 이와 같은 인과성이 없다.
4-5. 개체유도
1) 다차원 척도법(MDS : Multi - Dimensional Scaling)
다차원 척도법은 다차원 관측값 또는 개체들 간의 거리(distance)또느 비유사성(dissimilarity)을 이용하여 개체들을 원래의 차원보다 낮은 차원(보통 2차원)의 공간상에 위치시켜(spatial configuration) 개체들 사이의 구조 또는 관계를 쉽게 파악하고자 하는데 목적이 있다.
- 차원의 축소와 개체들의 상대적 위치 등을 통해 개체들 사이의 관계를 쉽게 파악하고, 공간상에 위치시켜(spatial configuration) 개체들 사이의 구조 또는 관계를 쉽게 파악하고, 공간적 배열에 주관적인 해석에 중점을 두고 있다.
5. 비정형 데이터의 분석
5-1. 텍스트 마이닝(Text Mining)
전통적인 데이터 마이닝의 한계를 벗어난 방법으로 인간의 언어로 이루어진 비정형 텍스트 데이터들을 자연어 처리방식을 이용하여 대규모 문서에서 정보 추출, 연계성 파악, 분류 및 군집화, 요약 등을 통해 데이터의 숨겨진 의미를 발견하는 기법이다.
- 자연어 처리(NLP : Natural Language Process)
* 인간의 언어 현상을 컴퓨터와 같은 기ㅖ를 이용해서 모사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야중 하나다.
* 자연 언어 처리는 연구대상이 언어이기 때문에 당연하게도 언어 자체를 연구하는 언어학과 언어 현상의 내적 기재를 탐구하는 언어 인지 과학과 연관이 깊다.
* 구현을 위해 수학적 통계적 도구를 많이 활용하며 특히 기계학습 도구를 많이 사용하는 대표적인 분야이다. 정보검색, QA 시스템, 문서 자동분류, 신문 기사 클러스터링, 대화형 Agent 등 다양한 응용이 이루어지고 있다.
5-2. 오피니언 마이닝(Opinion Mining)
오피니언 마이닝은 텍스트 마이닝의 한 분류로서, 특정 주제에 대한 사람들의 주관적 의견을 통계 수치화해 객관적 정보로 바꾸는 빅데이터 분석 기술이다.
- 텍스트 마이닝과 같이 문장을 분석하기 떄문에 자연어 처리 방법(NLP)을 사용하지만, 텍스트 마이닝은 문장 내 주제를 파악하고 오피니언 마이닝은 감정 뉘앙스 태도 등을 판별한다는 차이가 있다. 이 때문에 감정 분석(Sentiment Analysis)이라고도 불린다.
- 적용분야
* 텍스트 내 정보를 파악하기 위해 문장 구조, 문장간의 관계, 어휘 등을 분석해 키워드와 연관된 감성 어휘의 빈도를 중립 긍정 부정으로 분류하고 그 강도를 평가한다.
* 특정 서비스 및 상품에 대한 시장 규모 예측, 소비자의 반응, 입소문 분석 등에 활용되고 있으며, 최근 많은 기업이 자사와 자사상품 관련 댓글 SNS등을 실시간으로 분석해 이미지를 파악하고 대응 전략을 세워 사용하고 있다.
'빅데이터분석기사 > 필기' 카테고리의 다른 글
| (4과목) 빅데이터 결과 해석 ② (0) | 2024.03.28 |
|---|---|
| (4과목) 빅데이터 결과 해석 ① (0) | 2024.03.26 |
| (2과목) 빅데이터 탐색 ① (0) | 2024.03.19 |
| (1과목) 빅데이터 분석 기획 ③ (0) | 2024.03.18 |
| (1과목) 빅데이터 분석 기획 ② (2) | 2024.03.17 |

댓글