1. 분할(Segmentation)
이미지 분할(Image Segmentation)은 이미지 내에서 각 픽셀이 어떤 객체 또는 배경에 속하는지를 식별하는 과정이다. 분할은 크게 의미 분할(Semantic Segmentation), 사례 분할(Instance Segmentation), 총괄 분할(Panoptic Segmentation)의 세 가지 주요 유형으로 나뉜다.

1-1. 의미 분할(Semantic Segmentation)
의미 분할은 이미지 내의 모든 픽셀을 특정 클래스(예: 사람, 자동차, 나무 등)에 할당하는 과정이다. 이 과정에서 이미지 내 동일한 클래스에 속하는 모든 객체는 같은 레이블로 표시된다. 다시 말해, 개별 객체를 구분하지 않고, 모든 객체가 동일한 클래스로 그룹화된다.
예시) 도로 이미지에서 모든 차량을 '차량' 클래스로, 모든 보행자를 '보행자' 클래스로 표시하지만, 개별 차량이나 보행자를 구분하지는 않는다.

1-2. 사례 분할(Instance Segmentation)
사례 분할은 의미 분할의 한 단계 더 나아가, 이미지 내의 개별 객체를 식별하고 분할하는 과정이다. 같은 클래스에 속하는 객체라도 각각을 별도의 인스턴스로 구분하여 분할한다.
예시) 도로 이미지에서 '차량1', '차량2', '보행자1' 등과 같이 같은 클래스 내에서도 개별 객체를 구분하여 분할한다.
1-3. 총괄 분할(Panoptic Segmentation)
총괄 분할은 의미 분할과 사례 분할의 장점을 결합한 방식이다. 이 방식에서는 이미지를 '물체'와 '배경' 클래스로 분할하며, '물체' 클래스 내의 각 객체는 개별 인스턴스로 식별된다. 동시에 '배경' 클래스는 의미 분할처럼 처리된다.
예시) 도로 이미지에서 차량과 보행자는 각각 개별 인스턴스로 분할되며(사례 분할), 도로, 하늘, 나무와 같은 배경 요소는 클래스별로 그룹화 된다(의미 분할).
2. 성능척도와 데이터셋
2-1. 성능 척도
이미지 분할 태스크에서 모델의 성능을 평가하기 위한 여러 가지 척도들이 있다. 이러한 척도들은 모델이 얼마나 정확하게 각 픽셀의 클래스를 예측했는지, 그리고 실제 객체의 형태를 얼마나 잘 복원했는지를 측정한다. 주요 성능 척도로는 픽셀 정확도(Pixel Accuracy, PA), 평균 픽셀 정확도(Mean Pixel Accuracy, MPA), 교차-합집합 비율(Intersection over Union, IoU), 다이스 계수(Dice Coefficient)가 있다.
1) 픽셀 정확도(PA)
픽셀 정확도는 모델이 올바르게 분류한 픽셀의 비율을 측정한다. 전체 이미지 픽셀 중 올바르게 분류된 픽셀의 수를 전체 픽셀 수로 나눈 값이다. 이는 가장 직관적인 성능 지표 중 하나이지만, 클래스 간 불균형이 있을 때는 한 클래스에 편향된 결과를 낼 수 있다.
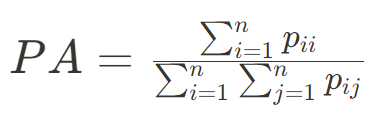
2) 평균 픽셀 정확도(MPA)
평균 픽셀 정확도는 각 클래스에 대한 픽셀 정확도의 평균을 취한 것이다. 이는 각 클래스를 동일하게 취급하여 전체 성능을 평가한다. 클래스 불균형이 있는 경우 PA보다 더 공정한 성능 평가를 제공할 수 있다.
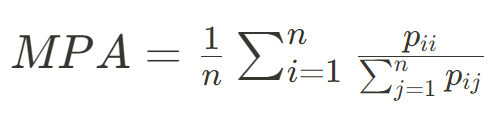
각 클래스별 정확도를 동등하게 고려하여 전체 성능을 평가한다.
3) 교차-합집합 비율(Intersection over Union, IoU)
IoU는 예측된 분할 영역과 실제 분할 영역의 교집합을 두 영역의 합집합으로 나눈 값이다. IoU는 객체 탐지 및 분할 태스크에서 널리 사용되는 지표로, 모델이 객체의 형태를 얼마나 정확하게 예측했는지를 평가한다. 각 클래스에 대해 개별적으로 계산할 수 있으며, 모든 클래스에 대한 평균 IoU(Mean IoU, MIoU)도 자주 사용된다.

여기서 TP (True Positive)는 올바르게 분류된 포지티브 픽셀의 수, FP (False Positive)는 잘못 분류된 포지티브 픽셀의 수, FN (False Negative)은 잘못 분류된 네거티브 픽셀의 수이다.
4) 다이스 계수(Dice Coefficient)
다이스 계수는 2배의 교집합 영역을 두 영역의 합으로 나눈 값으로, IoU와 유사한 개념이다. 주로 의료 이미지 분석 분야에서 사용되며, 분할된 영역의 유사성을 측정하는 데 효과적이다. 다이스 계수는 0에서 1 사이의 값을 가지며, 1에 가까울수록 높은 성능을 의미한다.

IoU와 유사하지만, 2TP를 분자에 사용하여 분할 영역의 중복을 더 강조한다.
2-2. Date Set
분할 데이터셋(Segmentation Dataset)은 이미지 분할 태스크, 즉 의미 분할(Semantic Segmentation), 사례 분할(Instance Segmentation), 또는 총관 분할(Panoptic Segmentation)을 위해 사용되는 데이터셋을 의미한다. 이러한 데이터셋은 각 픽셀 또는 객체에 대한 정확한 레이블이 포함된 이미지를 포함한다.
1) PASCAL VOC
- PASCAL VOC는 다양한 객체 탐지 및 분할 태스크를 위한 벤치마크 데이터셋 중 하나이다. 분할 태스크의 경우, 사람, 동물, 차량 등 여러 클래스에 대한 픽셀 수준의 레이블을 제공한다.
- 웹사이트: PASCAL VOC
2) MS COCO
- MS COCO(Microsoft Common Objects in Context) 데이터셋은 객체 탐지, 세분화(segmentation), 키포인트 탐지 등 다양한 컴퓨터 비전 태스크를 위해 설계되었다. 사례 분할과 총관 분할을 위한 풍부한 어노테이션이 포함되어 있다.
- 웹사이트: MS COCO
3) Cityscapes
- 도시 거리 장면을 중심으로 한 데이터셋으로, 자율 주행 자동차와 관련된 응용 프로그램을 위해 설계되었다. 고해상도 이미지에서 여러 차량, 보행자, 도로, 표지판 등에 대한 세밀한 픽셀 수준의 레이블을 제공한다.
- 웹사이트: Cityscapes
4) ADE20K
- ADE20K 데이터셋은 MIT에서 제작한 데이터셋으로, 실내 및 실외 장면을 포함하여 다양한 객체와 장면의 분할을 위한 풍부한 어노테이션을 제공합니다.
- 웹사이트: ADE20K
5) 데이터셋 준비
분할 데이터셋을 사용할 때는, 데이터 로딩 및 전처리 단계가 중요하다. TensorFlow, PyTorch 등 대부분의 딥 러닝 프레임워크는 이미지 데이터를 효율적으로 로드하고 전처리할 수 있는 도구를 제공한다. 예를 들어, TensorFlow에서는 tf.data API와 tf.image 모듈을 사용하여 데이터셋을 준비할 수 있다.
데이터셋을 사용할 때 주의해야 할 점은, 각 이미지와 해당하는 레이블(분할 마스크)이 정확히 일치해야 한다는 것이다. 분할 마스크는 일반적으로 이미지와 동일한 크기의 행렬로, 각 픽셀의 클래스 레이블(또는 인스턴스 ID)을 포함한다.
분할 태스크를 위한 데이터셋은 일반적으로 다양한 배경과 객체를 포함하여 모델의 일반화 능력을 평가할 수 있도록 설계되었다. 이러한 데이터셋을 통해 모델을 학습시키고 평가함으로써, 다양한 환경에서의 객체인식 및 분할 성능을 개선할 수 있다.
3. 추적(Tracking)
추적(Tracking)은 컴퓨터 비전 분야에서 매우 중요한 주제 중 하나이다. 대상이나 객체를 연속된 이미지 또는 비디오 프레임에서 식별하고, 그 위치를 시간에 따라 추적하는 과정이다. 이를 통해 객체의 움직임, 방향, 속도 등을 분석할 수 있다. 추적은 보안 감시, 자율 주행 차량, 인터랙티브 게임, 로봇 시각 등 다양한 응용 분야에서 활용된다.

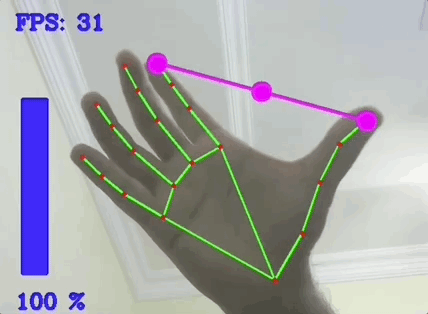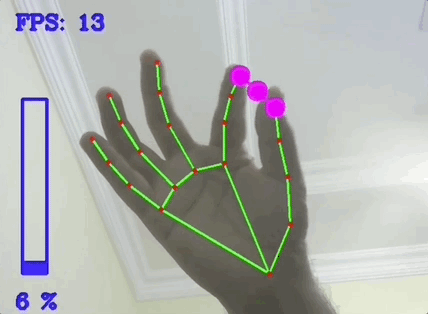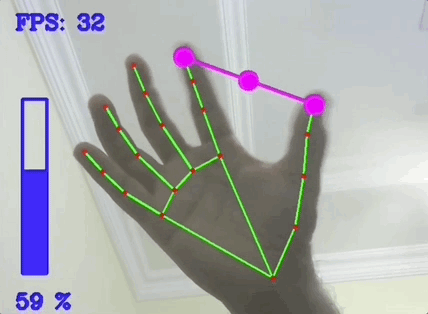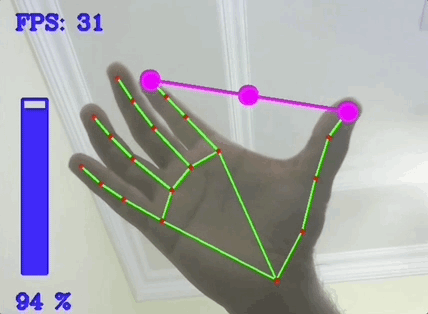
3-1. 추적과 알고리즘
추적 과정에서는 먼저 대상 객체를 식별하는 단계가 필요하다. 이를 위해 객체 탐지(object detection) 알고리즘이 사용된다. 객체가 한 번 탐지되면, 추적 알고리즘은 객체가 다음 프레임으로 이동하더라도 이를 계속해서 식별하고 위치를 업데이트한다. 이 과정에서 객체의 모양 변화, 가려짐, 조명 변화 등 다양한 도전을 극복해야 한다.
1) 추적 알고리즘
추적 알고리즘은 크게 두 가지 방법으로 분류할 수 있다: 온라인 추적과 오프라인 추적. 온라인 추적은 실시간으로 객체를 추적하며, 각 비디오 프레임이 주어질 때마다 객체의 위치를 업데이트 한다. 오프라인 추적은 모든 비디오 데이터를 미리 받아 이를 분석하여 객체의 경로를 찾는다. 대표적인 추적 알고리즘으로는 KCF(Kernelized Correlation Filters), SiamRPN(Siamese Region Proposal Network), GOTURN(Generic Object Tracking Using Regression Networks) 등이 있다.


2) VOT(Visual Object Tracking)
VOT는 시각적 객체 추적을 의미하며, 주로 단일 객체 추적(Single Object Tracking)에 초점을 맞춘다. VOT에서 중요한 요소는 정확성(객체 위치의 정확한 예측)과 견고성(다양한 방해 요소에 대한 추적의 지속성)이다. VOT 챌린지는 매년 개최되어, 다양한 추적 알고리즘의 성능을 평가하고 비교한다. 이는 추적 알고리즘의 발전에 크게 기여하고 있다.
3) MOT(Multiple Object Tracking)
MOT는 여러 객체를 동시에 추적하는 것을 의미한다. MOT에서는 객체 간의 상호 작용, 객체가 겹치거나 가려지는 상황, 동적인 환경 변화 등 더 많은 도전 과제를 해결해야 한다. MOT 알고리즘은 데이터 연관(data association) 기법을 사용하여 각 객체의 고유한 식별자를 유지하며 추적한다. 대표적인 MOT 알고리즘으로는 SORT(Simple Online and Realtime Tracking), DeepSORT(Deep Learning based SORT) 등이 있다.
추적 기술은 계속해서 발전하고 있으며, 더욱 정확하고 견고한 추적 성능을 달성하기 위한 연구가 활발히 이루어지고 있다. 추적 알고리즘의 발전은 컴퓨터 비전 기술의 전반적인 발전을 촉진하며, 이를 기반으로 한 응용 분야의 발전에도 크게 기여하고 있다.
4) MOTA (Multiple Object Tracking Accuracy)
MOTA는 여러 대상 객체를 추적할 때 사용되는 성능 평가 지표 중 하나이다. 여러 객체를 동시에 추적하는 과정에서 발생할 수 있는 오류들을 종합적으로 고려하여 추적의 정확도를 측정한다. MOTA는 다음 세 가지 주요 요소를 바탕으로 계산된다.
① False Positives (FP): 실제 객체가 없는 위치에 객체가 있다고 잘못 추적한 경우의 수이다.
② False Negatives (FN): 실제 객체를 추적하지 못한 경우의 수이다. 즉, 실제 객체가 있음에도 불구하고 그 위치를 추적하지 못한 경우이다.
③ ID Switches (IDSW): 추적 중에 객체의 식별자가 잘못 변경되는 경우의 수이다. 한 객체의 추적이 다른 객체로 잘못 연결되는 것을 말한다.

t는 시간 프레임을 나타내며, GT_t는 시간 프레임 t에서의 실제 객체 수이다. MOTA 값은 일반적으로 -∞에서 1 사이의 값을 가지며, 1에 가까울수록 추적 성능이 좋음을 의미한다.
5) 헝가리안 알고리즘 (Hungarian Algorithm)

헝가리안 알고리즘은 할당 문제를 해결하기 위한 알고리즘으로, 다수의 객체를 추적하는 과정에서 데이터 연관 문제를 해결하는 데 사용된다. 예를 들어, 다수의 추적 대상 객체와 다수의 관측된 객체 간의 최적의 매칭을 찾는 데 사용된다. 이 알고리즘은 각 객체 간의 비용(또는 거리) 행렬을 기반으로 작동하며, 전체 비용을 최소화하는 방식으로 각 추적 대상 객체를 관측된 객체에 할당한다.
- 헝가리안 알고리즘의 기본 단계
① 비용 행렬 생성: 각 추적 대상 객체와 관측된 객체 간의 비용(또는 거리)을 계산하여 행렬을 생성한다.
② 행과 열에서 가장 작은 값을 각각 빼서 비용 행렬을 수정한다.
③ 최소 수의 선을 사용하여 모든 0을 커버한다.
④ 모든 요소를 커버할 때까지 2와 3의 단계를 반복한다.
⑤ 최종적으로, 비용이 최소가 되도록 객체 간의 매칭을 결정한다.
헝가리안 알고리즘은 효율적으로 최적의 매칭을 찾을 수 있으며, MOT에서 객체 식별자의 일관성을 유지하는 데 중요한 역할을 한다. 이 알고리즘을 통해 ID 스위치의 수를 줄이고, MOTA 값을 개선할 수 있다.
3-2. SORT & DeepSORT
1) SORT (Simple Online and Realtime Tracking)
SORT는 "Simple Online and Realtime Tracking"의 약자로, 다중 객체 추적(MOT)을 위한 간단하면서도 효율적인 알고리즘이다. 이 알고리즘의 핵심 목적은 실시간 성능과 함께 높은 프레임 속도에서도 객체를 추적할 수 있는 능력에 있다. SORT는 주로 속도에 초점을 맞추어 설계되었으며, 따라서 복잡한 모델이나 깊은 학습 기반의 기능을 사용하지 않는다.
① 핵심 특징 및 작동 방식
- 탐지 기반 추적 : SORT는 각 프레임에서 객체 탐지기를 통해 얻은 탐지 결과를 기반으로 추적을 수행한다. 탐지 결과는 바운딩 박스 형태로 제공된다.
- 칼만 필터 : 각 객체의 움직임을 예측하고 추적하기 위해 칼만 필터를 사용한다. 이를 통해 객체의 위치와 속도를 추정한다.
- 헝가리안 알고리즘 : 탐지된 객체와 기존에 추적 중인 객체 간의 매칭을 최적화하기 위해 헝가리안 알고리즘을 사용한다.
- 속도 : 복잡한 데이터 연관 기법이나 딥러닝을 사용하지 않기 때문에, SORT는 매우 빠른 추적 속도를 제공한다.
2) DeepSORT (Deep Learning based SORT)
DeepSORT는 SORT 알고리즘을 기반으로 하면서, 딥러닝을 사용해 객체의 외형 정보를 추가로 활용하는 확장된 형태이다. DeepSORT는 특히 객체가 잠깐 사라졌다가 다시 나타나는 상황이나 다른 객체와 겹치는 상황에서도 좋은 성능을 보여주는 것이 특징이다.
① 핵심 특징 및 작동 방식
- 딥러닝 기반 특징 추출: DeepSORT는 객체의 외형 정보를 기반으로 한 특징 벡터를 딥러닝 모델을 통해 추출한다. 이를 통해 각 객체를 더 정확하게 식별할 수 있다.
- 칼만 필터와 헝가리안 알고리즘 : SORT와 마찬가지로 칼만 필터와 헝가리안 알고리즘을 사용하여 객체의 움직임을 추적하고, 탐지된 객체와 추적 중인 객체 간의 최적의 매칭을 찾는다.
- 추적 관리 : DeepSORT는 객체의 연속적인 추적을 위해 추적 객체의 생명주기를 관리한다. 객체가 일정 시간 동안 탐지되지 않으면 추적 목록에서 제거한다.
3) 비교 및 적용
- 속도 대 정확성 : SORT는 빠른 추적이 가능하지만, 객체의 외형 정보를 활용하지 않기 때문에 객체 간의 식별력이 떨어질 수 있다. 반면, DeepSORT는 딥러닝을 통한 특징 추출로 더 높은 정확성을 제공하지만, 계산 비용이 더 높다.
- 적용 분야 : SORT는 실시간 또는 고속 추적이 필요한 경우 유용하며, DeepSORT는 정확성이 중요한 응용 분야에서 더 적합하다.
4) Mediapipe
Mediapipe는 Google에서 개발한 오픈 소스 프레임워크로, 멀티미디어 콘텐츠, 특히 비디오, 이미지 및 오디오 스트림을 처리하기 위한 강력한 도구 모음이다. 이 프레임워크는 머신러닝 모델을 사용하여 다양한 비전 기반 태스크를 수행할 수 있도록 설계되었다. 여기에는 얼굴 감지, 손가락 추적, 포즈 추정 등이 포함된다. Mediapipe는 이러한 기능을 실시간으로 실행할 수 있으며, 다양한 플랫폼과 장치에서 사용할 수 있도록 최적화되어 있다.
Mediapipe는 내부적으로 여러 컴포넌트와 파이프라인을 구성하여, 입력된 스트림을 처리하고 결과를 출력한다. 개발자는 이 프레임워크를 사용하여 복잡한 머신러닝 및 비전 처리 알고리즘을 쉽게 통합할 수 있으며, 높은 수준의 정확성과 효율성을 달성할 수 있다.
5) BlazeFace
BlazeFace는 Google이 개발한 경량 얼굴 감지 모델로, 특히 모바일 장치와 실시간 애플리케이션을 위해 설계되었다. 이 모델은 속도와 효율성을 최적화하기 위해 특별히 설계되었으며, 실시간으로 얼굴을 감지하는 데 필요한 정확성을 제공한다. BlazeFace는 작은 크기의 얼굴과 다양한 포즈에서도 얼굴을 잘 감지할 수 있으며, 이를 통해 다양한 환경에서 얼굴을 효과적으로 감지할 수 있다.
BlazeFace는 Mediapipe 프레임워크 내에서 사용할 수 있는 모델 중 하나로, 실시간 비디오 스트림에서 얼굴을 감지하는 애플리케이션을 빠르게 개발할 수 있도록 지원한다. 이 모델은 특히 모바일 장치에서의 얼굴 인식, AR(증강 현실) 효과, 카메라 애플리케이션 등에 유용하게 사용될 수 있다.
'딥러닝 프레임워크 > 이미지 처리' 카테고리의 다른 글
| CNN_고급활용 (1) | 2024.04.08 |
|---|---|
| CNN_전이학습 (0) | 2024.04.04 |
| CNN(Convolution Neural Network) (0) | 2024.04.02 |

댓글