1. 전이 학습(Transfer Learning)
1-1. 전이 학습(Transfer Learning)의 개요
전이 학습은 한 분야에서 얻은 지식을 다른 분야의 문제 해결에 적용하는 학습 방식이다. 딥러닝, 특히 이미지 분류 문제에서 이 방식은 뛰어난 성능을 보여주며 널리 사용된다. 기존에 학습된 딥 뉴럴 네트워크(DNN)를 다른 데이터셋이나 문제에 적용하여 빠르고 정확한 결과를 얻을 수 있다. 이는 네트워크가 다양한 이미지로부터 보편적인 특징이나 패턴을 학습했기 때문에 가능하다.

1-2. 네트워크에서의 특징 학습
1) Low-level features
네트워크의 초기 층에서 학습되며, 이미지의 색, 경계와 같은 기본적인 요소를 포함한다.
2) High-level features
네트워크의 깊은 층에서 학습되며, 객체의 패턴이나 형태와 같은 보다 복잡한 정보를 의미한다.
1-3. 대표적인 데이터셋
1) ImageNet

ImageNet 데이터셋은 이미지 분류 모델 학습에 주로 사용되며, 자동차부터 고양이에 이르기까지 1000개 클래스에 걸쳐 총 1400만 개의 이미지를 포함한다. ImageNet을 기반으로 학습된 모델들은 사람의 분류 오류율인 5.1%를 넘어서는 성능을 보여주었다.
2) COCO (Common Objects in Context)
- 목적: 이미지 인식, 분할, 그리고 캡셔닝을 위한 데이터셋
- 특징: 330,000개 이상의 이미지에서 80개 카테고리에 대한 200만 개의 레이블이 붙은 인스턴스
3) PASCAL VOC (Visual Object Classes)
- 목적: 이미지 분류, 객체 탐지, 객체 분할을 위한 데이터셋.
- 특징: 여러 연도에 걸쳐 발표된 데이터셋으로, 20개의 카테고리에 속하는 객체를 포함하고 있음.
4) CIFAR-10/CIFAR-100
- 목적: 이미지 분류.
- 특징: CIFAR-10은 10개 클래스에 60,000개의 32x32 이미지를, CIFAR-100은 100개 클래스에 같은 수의 이미지를 포함.
1-4. 전이 학습의 구현
전이 학습을 구현하기 위해 여러 주요 CNN 구조가 사용된다. AlexNet, VGG, GoogleNet, ResNet 등이 대표적이며, 이들은 네트워크의 기반이 되어 다양한 문제를 해결하는 데 기여한다. TensorFlow, Keras, PyTorch와 같은 딥러닝 프레임워크는 이러한 모델들을 API로 제공하여 쉽게 사용할 수 있다.
1) AlexNet
- 개요: AlexNet은 2012년 ImageNet 대회(ILSVRC)에서 우승한 구조로, 깊은 합성곱 신경망(CNN)의 가능성을 널리 알린 모델이다. Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton에 의해 개발되었다.

- 구조 및 특징
① 5개의 합성곱 층(convolutional layers)과 3개의 완전 연결 층(fully connected layers)으로 구성된다.
② ReLU(Rectified Linear Unit) 활성화 함수를 사용하여 비선형성을 도입했다.
③ 과적합(overfitting)을 방지하기 위해 드롭아웃(dropout)과 데이터 증강(data augmentation) 기법을 사용했다.
④ GPU를 사용한 효율적인 훈련 방식을 도입하여 당시로서는 매우 빠른 학습 속도를 달성했다.
2) VGG (Visual Geometry Group)
- 개요: VGG는 옥스퍼드 대학의 Visual Geometry Group에 의해 개발된 모델로, 2014년 ILSVRC에서 뛰어난 성능을 보인다.

- 구조 및 특징
① VGG16과 VGG19 두 가지 버전이 가장 유명하며, 각각 16개, 19개의 층으로 구성되어 있다.
② 모든 합성곱 층에서 3x3 필터를 사용하며, 층이 깊어질수록 필터의 수가 증가한다.
③ Max pooling을 통해 특징 맵(feature map)의 크기를 줄인다.
④ 성능 향상에 비해 구조가 단순하고 직관적이라는 점에서 많은 연구에서 기반 모델로 활용된다.
3) GoogleNet (Inception v1)
- 개요 : GoogleNet은 Google에서 개발한 모델로, Inception 구조를 도입한 것이 특징이다. 2014년 ILSVRC 대회에서 우승했다.

- 구조 및 특징
① 깊이와 너비를 증가시키면서도 계산 비용을 효율적으로 관리할 수 있는 Inception 모듈을 사용한다.
② 여러 크기의 필터와 풀링을 병렬적으로 적용하여 다양한 스케일의 특징을 추출한다.
③ 1x1 합성곱을 사용하여 차원을 줄이는 기법을 도입, 계산 효율성을 높였다.
④ 22층으로 구성되어 있으며, 매우 깊은 네트워크임에도 불구하고 계산 비용을 효율적으로 관리한다.
4) ResNet (Residual Network)
- 개요: ResNet은 Microsoft에서 개발한 모델로, 2015년 ILSVRC에서 우승했다. 깊은 네트워크에서 발생할 수 있는 소실된 기울기(vanishing gradient) 문제를 해결하기 위해 잔차 연결(residual connections)을 도입했다.

- 구조 및 특징
① 34, 50, 101, 152 등 다양한 층으로 구성된 여러 버전이 있다.
② 잔차 블록(residual block)은 입력을 출력에 직접 더해줌으로써, 네트워크가 학습해야 할 목표를 잔차 함수로 변환한다. 이는 깊은 네트워크에서의 학습을 용이하게 한다.
③ 이러한 구조 덕분에 수백 층이 넘는 매우 깊은 네트워크를 효과적으로 학습할 수 있으며, 이미지 분류뿐만 아니라 다양한 컴퓨터 비전 태스크에서 우수한 성능을 보인다.
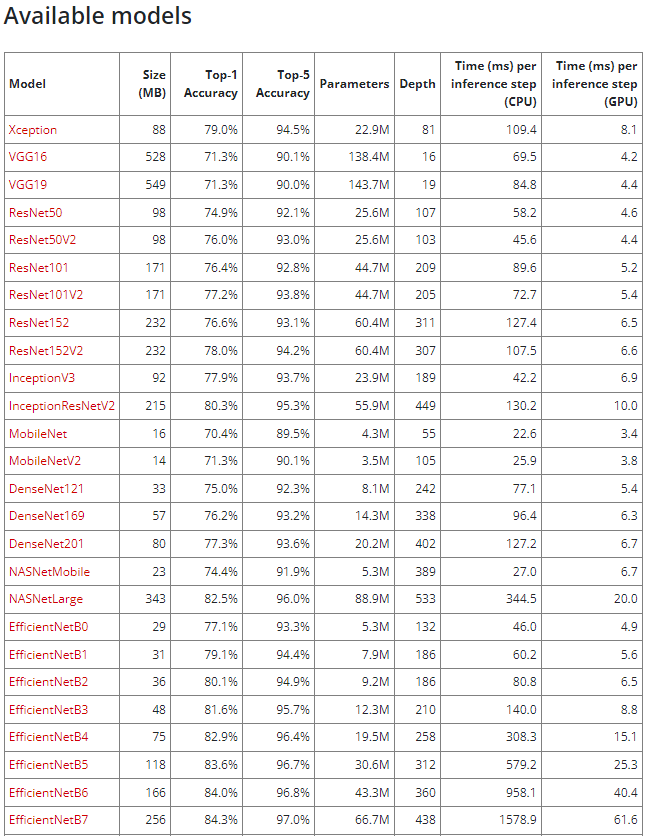
5) Tensorflow API
Keras documentation: Keras Applications
Keras Applications Keras Applications are deep learning models that are made available alongside pre-trained weights. These models can be used for prediction, feature extraction, and fine-tuning. Weights are downloaded automatically when instantiating a mo
keras.io
'딥러닝 프레임워크 > 이미지 처리' 카테고리의 다른 글
| CNN_고급활용(2) (2) | 2024.04.12 |
|---|---|
| CNN_고급활용 (1) | 2024.04.08 |
| CNN(Convolution Neural Network) (0) | 2024.04.02 |

댓글