1. 분류의 개요
머신러닝은 인공지능 분야 중 하나로, 데이터를 이용하여 패턴을 학습하고 예측하는 기술이다. 이 중에서 분류모델은 데이터를 특정 카테고리나 그룹으로 분류하는 모델이다.
2. 분류모델의 개념
분류모델은 데이터를 분류하는 모델로, 입력 데이터에 대해 사전에 정해진 카테고리에 속하는지 여부를 판단한다.
지도학습에서는 미리 정해진 레이블(label) 정보를 이용하여 모델을 학습시키고, 새로운 데이터가 들어오면 해당 데이터를 분류한다. 반면, 비지도학습에서는 레이블 정보 없이 데이터의 패턴을 파악하여 그룹을 형성하거나 이상치를 찾아낸다.
3. 분류모델의 종류
3-1. 의사결정나무(Decision Tree)
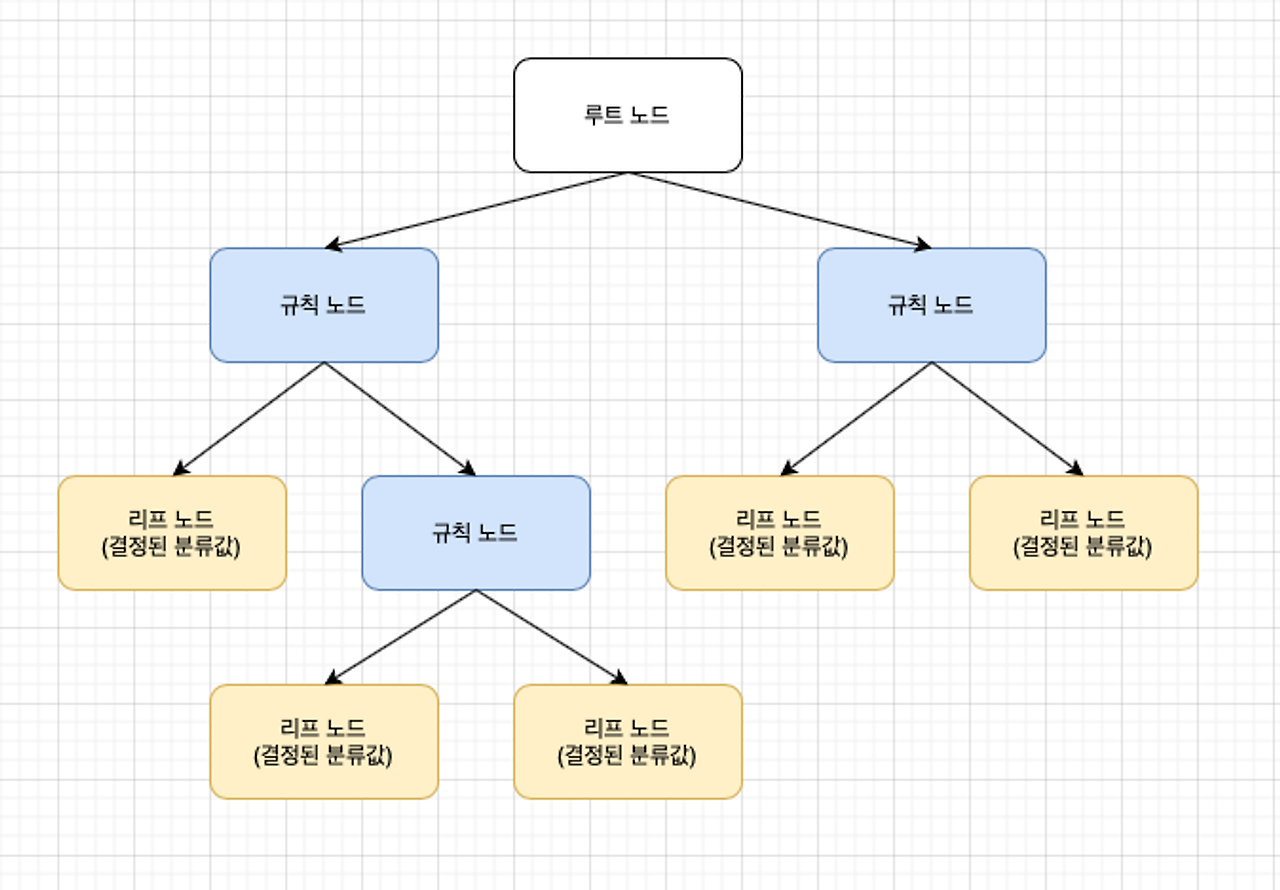
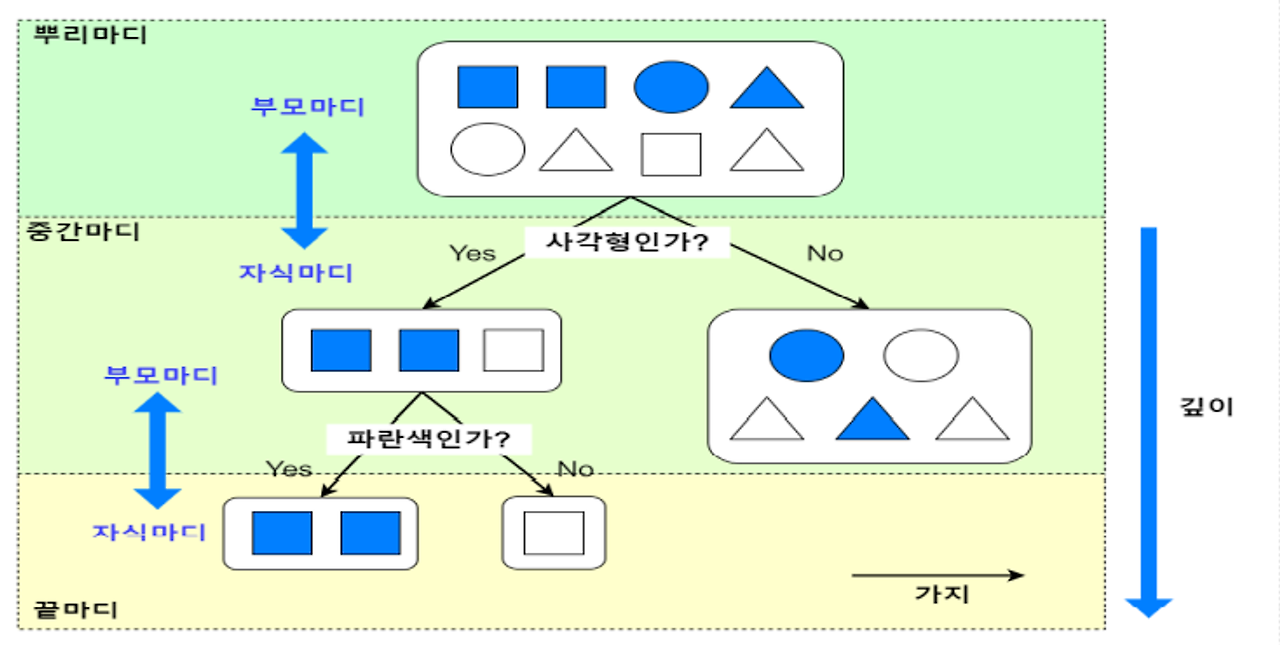
1) 데이터를 분할하여 트리 구조로 표현하는 모델
2) 각 노드에서는 데이터를 가장 잘 분류할 수 있는 특성을 선택한다.
3) 각 분기점에서 가장 정보량이 많은 특성을 선택한다.
- 지니계수(Gini Index)
의사결정나무에서 분기점을 구성할 때 사용되는 지니계수(Gini Index)는 해당 분기점에서 데이터가 얼마나 잘 분류되는지를 나타내는 지표이다. 지니계수가 낮을수록 해당 분기점에서 데이터가 잘 분류된다.


3-2. k-최근접 이웃(k-Nearest Neighbor)
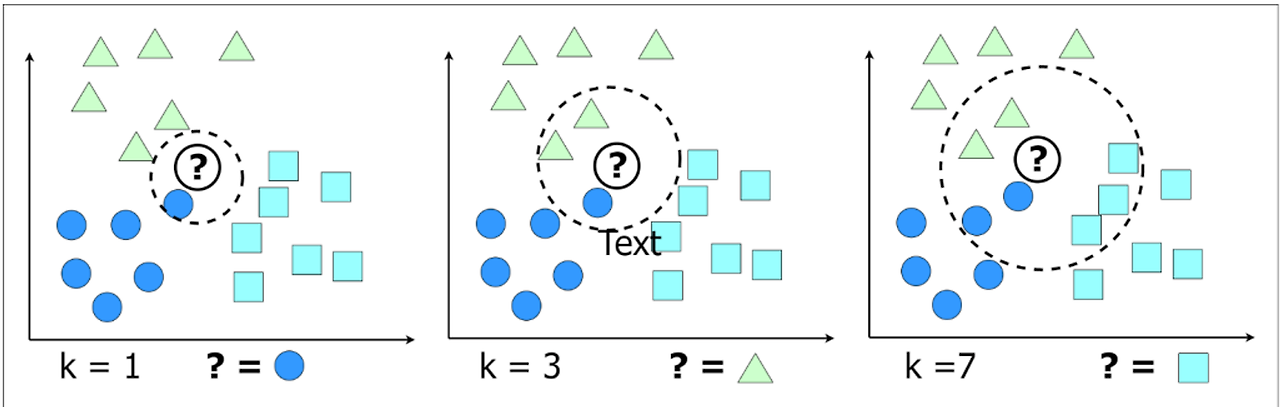
k-최근접 이웃(k-Nearest Neighbor)은 분류 모델 중 하나로써, 새로운 데이터와 가장 가까운 k개의 데이터를 찾아 그 중 다수결로 새로운 데이터의 레이블을 결정하는 방식이다. 예를 들어, 새로 들어온 고객의 정보를 바탕으로 고객이 VIP 고객인지 아닌지를 판단하는 모델을 만들 경우, k-최근접 이웃 알고리즘을 사용하여 유사한 특성을 가진 다른 고객들의 정보를 기반으로 새로운 고객의 레이블을 결정할 수 있다.
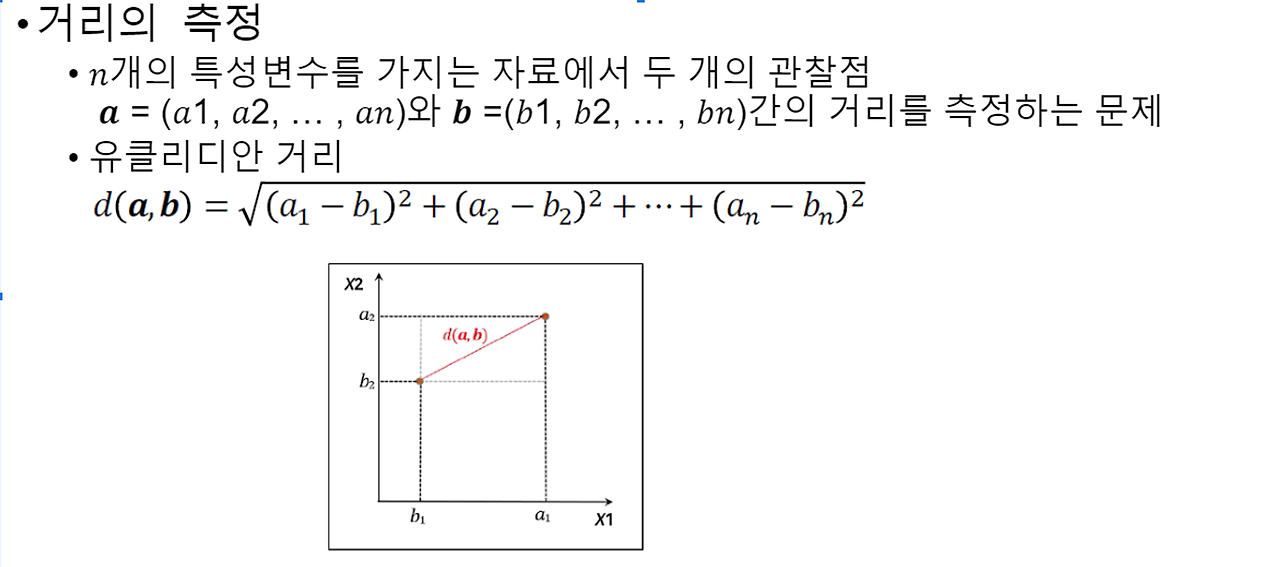
거리 측정 방법에는 유클리디언 거리, 맨하탄 거리, 코사인 유사도 등 다양한 방식이 있다. 유클리디언 거리는 가장 기본적인 거리 측정 방법으로, 두 점 사이의 직선 거리를 계산한다. 맨하탄 거리는 두 점 사이의 거리를 계산할 때 좌표축을 따라 이동한 거리의 합을 계산한다. 코사인 유사도는 두 벡터 간의 방향을 비교하여 유사도를 측정하는 방식으로, 문서 분류 분야에서 자주 사용된다.



- 거리측정

1) 각 변수들의 스케일이 유사하도록 스케일링(Z score, min-max)을 사용한뒤 스케일링 하는 것이 적절하다.
3-3. 로지스틱 회귀(Logistic Regression)
로지스틱 회귀(Logistic Regression)는 입력 데이터가 어떤 분류에 속할 확률을 예측하는 모델이다. 이진 분류(binary classification)와 다중 분류(multi-class classification)에 모두 사용될 수 있다.
로지스틱 회귀는 선형 회귀(Linear Regression)와 유사한 점이 있지만, 선형 회귀에서는 예측값이 연속적인 값을 갖는 반면 로지스틱 회귀에서는 이진 분류에서는 0 또는 1을, 다중 분류에서는 각 클래스에 대한 확률 값을 갖는다. 이를 위해 로지스틱 회귀는 시그모이드 함수(Sigmoid Function)를 사용하여 입력 데이터를 확률 값으로 변환한다.
로지스틱 회귀는 입력 데이터와 가중치를 선형 결합한 값을 시그모이드 함수에 적용하여 0과 1사이의 값으로 변환한다. 이를 통해 분류 모델에서 입력 데이터가 어떤 분류에 속할 확률을 예측할 수 있다.
로지스틱 회귀는 분류 모델 중에서도 단순하면서도 성능이 우수한 모델로, 이진 분류와 다중 분류에서 모두 사용됩니다. 또한, 로지스틱 회귀는 알고리즘이 간단하고 계산이 빠르기 때문에 대용량 데이터에 대한 학습이 가능하다.
하지만 로지스틱 회귀 모델은 데이터의 선형적 분리가 어려울 경우 성능이 낮아질 수 있다. 따라서 로지스틱 회귀 모델을 사용할 때는 데이터의 선형적 분리 여부를 확인하고 적절한 전처리나 모델링 기법을 사용하여 성능을 개선해야 한다.
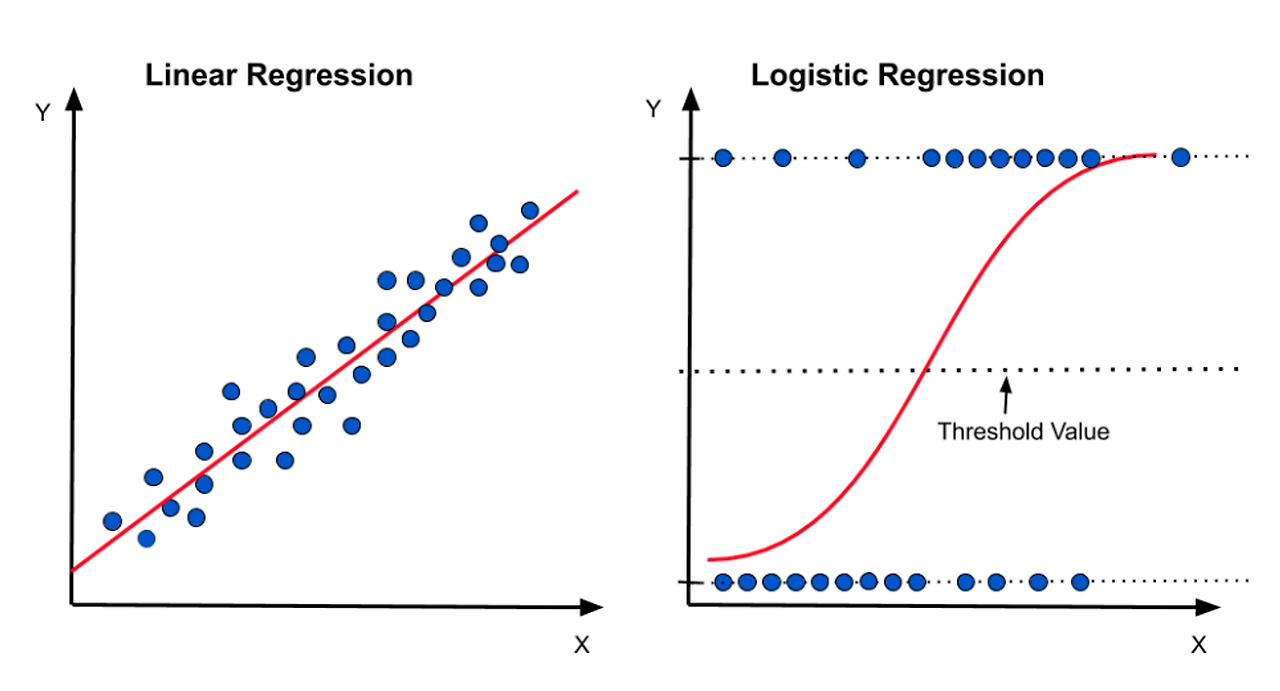
- 로지스틱 회귀분석 알고리즘
1) Odds(오즈)
오즈란 성공할 확률이 실패할 확률의 몇배인지를 나타내는 값이다. 로지스틱 회귀분석에서 이 오즈식을 변환하여각 범주에 분류될 확률 값을 추정하는데 사용한다. 각 범주별 오즈값을 비율로 나타낼 수 있는데 이를 오즈비라한다. 아래 수식에서 독립변수 𝑥_𝑘가 한 단위 증가할 때 ℯ의 𝛽𝑘제곱만큼 오즈값(성공확률)이 증가한다는걸 알 수있다.

2) 로짓변환
오즈값은 0~∞ 값을 갖기 때문에 비대칭성을 띤다는 문제가 있다. 이러한 문제를 해결하기 위해서 오즈에 로그값을 취한 것이 로짓(logit)이며, 이를 로짓 변환이라한다. 즉, 오즈의 값의 범위를 −∞ < logit(p) < ∞ 로 확장하기 위한 방법을 로짓 변환이라고 한다.
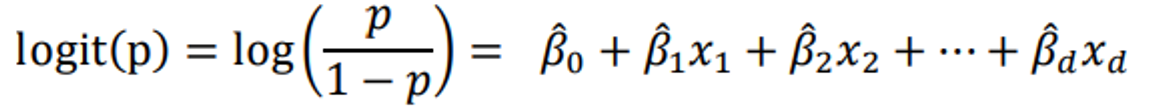
3) 시그모이드
시그모이드 함수는 로지스틕 회귀분석과 인공신경망 분석에서 사용된다. 시그모이드 함수는 로짓함수와 역함수관계이기 때문에 로짓함수를 통해 시그모이드 함수가 도출된다. 로지스틱 회귀분석에 사용되는 시그모이드 함수는 주어진 확률값을 기준으로 사건이 발생할지 안할지를 결정하는 역할을 한다.

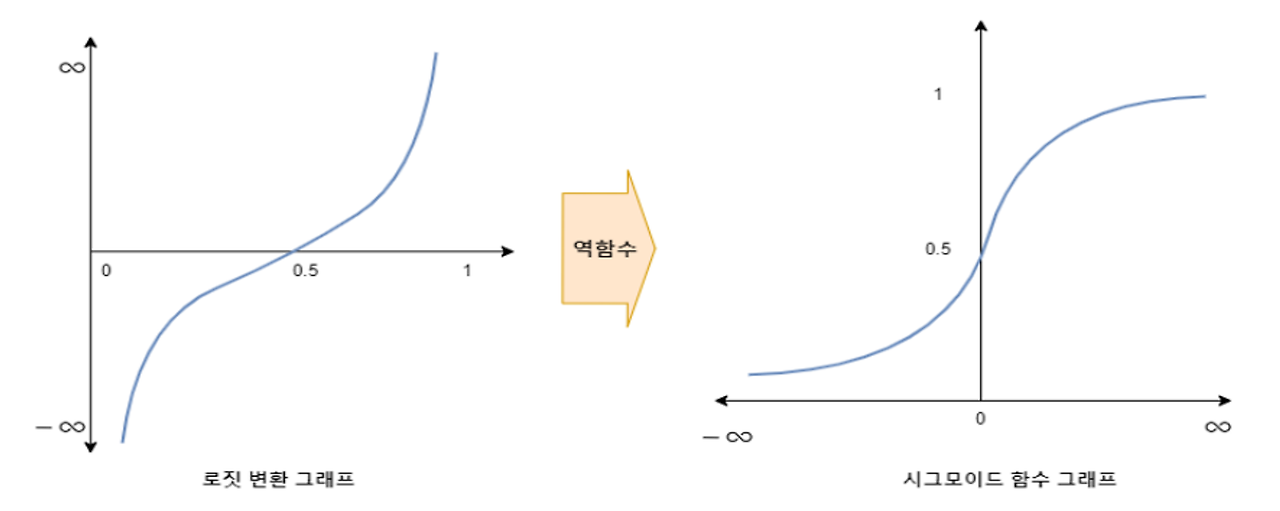
4. 분류모델의 학습 방법
4-1. 배치 학습(Batch Learning)
1) 전체 데이터셋을 한 번에 모델에 입력하여 학습하는 방식
2) 대용량 데이터에 적합하지 않을 수 있음
3) 학습된 모델은 새로운 데이터가 들어올 때마다 모델 전체를 재학습해야 함
4-2. 온라인 학습(Online Learning)
1) 새로운 데이터가 들어올 때마다 모델을 조금씩 업데이트하는 방식
2) 대용량 데이터에 적합하며, 실시간 예측이 필요한 경우 사용될 수 있음
3) 예측 오류가 발생하면 이를 학습에 반영해 모델을 개선할 수 있음
5. 분류모델 평가
분류모델의 성능을 평가하기 위해서는 다양한 지표를 사용할 수 있다.
5-1. 혼동행렬(Confusion Matrix)
분류 분석에서 평가 지표란 구축된 모델이 데이터를 얼마나 잘 분류하는지에 관한 평가이다. 즉, 예측값과 실제값을 비교하여 맞는 경우(Correct)와 틀린 경우(Incorrect)로 구분된다. 이러한 결과를 교차표 형태로 정리한 것을 오분류표라고 하며, Confusion Matrix(혼동 행렬)이라고도 한다.

- 정확도(Accuracy)
1) 전체 예측 중 실제값과 일치한 비율
2) 이진 분류(binary classification)에서는 실제값이 True인 경우의 비율, 다중 분류(multi-class classification)에서는 전체 클래스 중 맞춘 클래스의 비율

- 정밀도(Precision)
1) Positive로 예측한 데이터 중 실제값이 Positive인 비율
2) 거짓 양성(False Positive)을 최소화하는 것이 목적인 경우 사용됨

- 재현율(Recall)
1) 실제값이 Positive인 데이터 중 Positive로 예측한 비율
2) 거짓 음성(False Negative)을 최소화하는 것이 목적인 경우 사용됨

5-2. F1 스코어(F1 Score)
1) 정밀도와 재현율의 조화 평균(Harmonic Mean)
2) 정밀도와 재현율이 모두 2높은 모델일수록 F1 스코어가 높음

5-3. ROC 곡선과 AUC
1) 이진 분류에서 사용되는 평가 지표
2) 모델의 True Positive Rate와 False Positive Rate를 변화시키면서 그래프를 그리고, 이를 기반으로 AUC(Area Under Curve)를 계산함
3) AUC 값이 높을수록 모델의 성능이 좋다고 판단할 수 있음

'머신러닝과 빅데이터 분석 > Machine Learning(지도학습)' 카테고리의 다른 글
| 분류 분석 2 (0) | 2024.03.15 |
|---|---|
| 회귀분석 (0) | 2024.03.12 |
| 머신러닝 (0) | 2024.03.11 |

댓글