1. DataFrame의 속성 정보
1-1. 데이터 크기 및 속성
1) 데이터 크기(shape)
데이터 프레임을 생성하면 가장 먼저 할 일은 데이터의 크기를 확인하는 것이다. DataFrame을 만들거나 데이터를 생성하거나 조작할 때는 데이터 크기를 반드시 확인해야 한다. DataFrame의 Shape은 모두 2차원의 테이블 형태로 출력된다. (행_Row, 열_Column) 형태로 출력되며, Shape을 통해 행과 열의 총개수를 확인할 수 있다.
2) 데이터의 정보 (info)
데이터의 크기를 확인한 후에는 DataFrame의 속성을 파악해야 한다. 어떤 데이터들이 들어있고 Column과 Index의 이름이 무엇인지 등 해당 DataFrame 안에 Data들의 정보를 파악해야 한다. 이 때 사용하는 함수가 info다. information의 앞 글자로 DataFrame의 기초 정보를 제공해 준다.
3) 데이터의 요약값(describe)
- DataFrame의 데이터들의 요약값을 보여주는 함수로 기본적인 통계정보를 제공한다. 기본적으로 누락데이터(null)은 제외하고 각 Column의 계산 결과를 나타내며, 숫자 데이터만을 통계로 보여준다. 만약 숫자가 아닌 문자(Object)에 대한 요약 값을 보고 싶은 경우에는 include=['O']를 입력해야 한다. 만약 숫자와 문자 모두 포함한 요약값을 필요로 할 경우 include='all'을 입력하면 된다.
- describe 함수로 알 수 있는 정보는 숫자 데이터의 경우 Count(개수), mean(평균), std(표준편차), min(최소값), max(최대값), 사분위수다. 문자형 데이터의 경우 Count(갯수), Unique(중복을 제외한 데이터의 갯수), top(각 열의 가장 많이 출현한 데이터), freq(각 열의 가장 많이 출현한 데이터의 개수)를 나타낸다.
- 데이터프레임.describe(percentiles=(0과1사이의 범위의 수), include= [’O’] or ‘all’)
2. DataFrame의 인덱싱과 슬라이싱
2-1. Column(열)
1) 속성으로 접근하기
DataFrame은 각 column을 속성으로 사용할 수 있다. 예를 들어 'Name'이라는 열(Column)이 있다면 DataFrame.Name이라는 속성으로 해당 Column에 접근할 수 있다. 이렇게 접근하는 경우, 해당 결과는 Series로 반환된다. 만약 해당 칼럼의 값을 가져와야 할 경우에는 tolist() 함수를 사용하여 List에 값을 저장할 수 있다.
그다음, 특정 값을 선택하거나 범위를 지정할 경우는 대괄호([])를 사용하여 해당 위치 값을 지정하여 인덱싱과 슬라이싱이 가능하다.
데이터프레임.컬럼명 ⇒ Series로 반환
데이터프레임.컬럼명.tolist() ⇒ List로 변환
2) 위치값으로 접근
DataFrame에서는 속성으로 열(column)에 접근하는 방식 외에도 대괄호( )를 사용하여 직접 열을 가져올 수 있다. 추출된 결과는 Series이며, 데이터를 저장하기 위해서는 List를 사용할 수 있다. 또한, 대괄호( )를 한 번 더 사용하여 데이터를 선택하거나 범위를 지정할 수 있다.
데이터프레임[컬럼명] ⇒ Series로 반환
데이터프레임[컬럼명] .tolist() ⇒ List로 변환
여러 개의 Column을 동시에 가져오려면, 가져오길 원하는 Column명을 리스트로 묶어서 전달하면 된다. 하지만 이 경우, 반환되는 결과는 DataFrame을 유지하기 때문에 Series처럼 결과값만 리스트로 만들 수는 없다.
데이터프레임.[ [컬럼명1, 컬럼명2, 컬럼명3, ..] ] ⇒ dataFrame
2-2. Row(행)
DataFrame에서 행을 인덱싱 하려면 인덱서(Indexer)를 사용한다. 인덱서에는 두 가지 유형이 있다. 하나는 정수 타입의 위치 값을 사용하는 방식(iloc)이고, 다른 하나는 Index와 Column명을 사용하는 방식(loc)이다. 우리는 일반적으로 정수 타입의 위치 값을 많이 사용한다. 인덱스(Index)는 행의 이름을 말하며, 행 번호는 행의 위치 정보를 나타낸다.
1) loc
loc는 Index와 Column명을 사용하는 방식이다. Index와 Column명이 숫자로 되어있는 경우 loc뒤에 대괄호 ( ) 안에 숫자를 입력하고 문자형식의 Index와 Column명은 문자(str)로 입력해야 한다. 특정 범위를 슬라이싱 하는 경우는 List와 마찬가지로 콜론 ( : )을 사용하여 범위를 지정할 수 있으며, 범위가 아닌 필요한 행들만 복수로 추출하기 위해서는 대괄호 ( )안에 각 Index명을 List형태로 입력하여 사용할 수 있다.
데이터프레임.loc[Index명] # loc 생략 가능(숫자인 경우에만)
데이터프레임.loc[Index명 : Index명] # loc 생략 가능, 지정범위는 시작과 끝을 모두 포함한다.
데이터프레임.loc[ [Index명1, Index명2, Index명3, …. ] ] # loc 생략 불가
2) iloc
iloc는 실제 행의 번호를 이용하여 인덱싱과 슬라이싱을 하는 방식이다. Index는 각 행에 부여된 이름이며, 실제 행의 위치 정보는 행의 번호로 표현할 수 있다. DataFrame의 모든 행은 0부터 시작하는 숫자 형태로 표현된다. 이를 활용하여 인덱싱과 슬라이싱이 가능하다. iloc 사용법은 loc와 같다.
데이터프레임.iloc[ 행번호 ]
데이터프레임.iloc[ 행번호 : 행번호 ]
데이터프레임.iloc[ [행번호1, 행번호2, 행번호3, … ] ]
2-3. 행과 열 동시 인덱싱
행과 열을 동시에 인덱싱하기 위해서는 loc 또는 iloc 중 하나를 사용하여 행과 열을 같이 인덱싱할 수 있다. 그러나 둘의 차이는 loc는 행과 열의 이름(Index, Columns)을 사용하고, iloc의 경우는 위치 정보, 즉 숫자로 인덱싱을 할 수 있다는 점이다. 각각의 장단점은 없지만 상황에 맞게 위치 값을 사용해야 할 경우는 iloc을, 행과 열의 이름을 사용해야 할 경우에는 loc를 사용하면 된다.
3. DataFrame의 데이터 변경
- 데이터 타입 변경
DataFrame을 생성할 때, 문자 또는 숫자 데이터를 다른 형태의 데이터로 변경해야 할 경우가 있다. 예를 들어, 정수(int) 형태의 데이터를 실수(float) 형태의 데이터로 변경하거나, 문자로 된 날짜를 실제 시간 타입(datetime) 데이터로 변경해야 할 경우가 있다. 이러한 경우, astype() 함수를 이용하여 데이터를 변경하거나 DataFrame을 만들 때 해당 컬럼을 시간 타입의 데이터로 변경할 수 있다.
3-1. Data Type 변경
DataFrame을 생성하여 info를 확인하거나 dtypes 함수를 이용하여 데이터의 타입을 확인할 수 있다. 이때 날짜와 같은 형식의 데이터가 문자형태로 들어가는 경우가 발생할 수 있다. 문자 형태의 시간 데이터는 연산이 어렵지만 Datetime 형식의 데이터는 연산과 다양한 변형이 가능하여 날짜 형식의 데이터를 활용할 때 유용하다. 이러한 경우 str ⇒ Datetime으로 변형해야하는데, 이러한 경우 사용되는 함수가 to_datetime()다. 또한, Datetime만이 아니라 정수를 실수형태로 변경하거나 숫자를 문자로 변경을 원하는 경우가 있을 수 있다. 이러한 경우 Column을 기준으로 데이터의 Type을 변경할 수 있는데 이때 사용하는 함수가 astype()다.
1) 날짜형식 데이터 변형(pd.to_datetime)
문자 또는 숫자 타입의 데이터를 날짜 타입의 데이터로 변경할 때 사용하는 함수가 to_datetime함수다. to_datetime 함수는 날짜 형식을 지정할 수 있는데, format 인자를 지정하여 사용할 수 있다. Datetime 형식의 데이터는 연(year), 월(month), 일(day)를 속성으로 사용할 수 있어 날짜형식의 데이터의 연산과 특정 시간을 지정하기 매우 편해진다.
pd.to_datetime(데이터프레임[컬럼명], format= ‘형식지정자’)
| 형식 지정자 | 의미 | 결과 |
| %a | 요일(단축) | Mon, Tue,… |
| %A | 요일 | Monday, Tuesdaty,.. |
| %w | 요일(숫자) | 0, 1, 2, 3, 4, 5, 6 |
| %d | 일(2자리) | 01,02,03, … |
| %b | 월(단축) | Jan, Feb, … |
| %B | 월 | January, Feburary, … |
| %m | 월(숫자) | 01, 02, 03, … |
| %y | 연(2자리) | 20, 21, 22,… |
| %Y | 연(4자리) | 2020, 2021, 2022, … |
| %H | 시간(24h) | 00, 01, 02, 03, … 23 |
| %I | 시간(12h) | 01, 02, 03, … , 24 |
| %M | 분 | 00, 01, 02, …, 59 |
| %s | 초 | 00, 01, 02, …, 59 |
2) datetime의 속성 활용(dt)
datetime 유형의 데이터에서는 각 속성을 활용할 수 있다. 예를 들어, datetime 유형의 데이터에서 연도만 추출하려면 데이터를 선택하고 해당 데이터의 year 속성을 사용하여 연도만 추출할 수 있다. 월, 일, 요일 등도 추출할 수 있다. 추출된 데이터는 정수형(int)으로 변경되어 다양한 연산에 사용될 수 있다. 만약 데이터가 아닌 Column 전체에서 특정 속성을 사용하려면 dt 접근자를 사용하여 데이터를 추출할 수 있다.
3) 다양한 형태의 변환(astype)
다양한 형태의 데이터 타입 (문자, 날짜, 숫자 등)을 서로 변경시키는 방법으로는 astype() 함수를 사용할 수 있다. 문자를 날짜 형식으로 변환할 때는 to_datetime을 사용하지만, 날짜를 문자 형식으로 바꿀 때는 astype을 사용한다. 또한, 숫자를 문자로, 정수를 실수로 바꾸는 등 날짜 형식 외에도 데이터의 타입 변경은 astype을 사용할 수 있다.
데이터프레임[’컬럼명’].astype(변경할 type)
3-2. 누락데이터 변경
누락 데이터란 데이터의 값이 없는 것을 말한다. 이는 NaN(Not a Number), NA(Not Available), Null과 같이 아무것도 없는 데이터를 의미한다. 이러한 누락값은 데이터 생성이나 이동 과정에서 발생할 수 있다. 누락된 값들은 데이터 분석에 방해요소가 되기 때문에 이를 처리하는 방법은 데이터 분석에 있어 중요한 요소다.
1) 누락 데이터 확인
DataFrame에서 누락 데이터를 확인하는 방법은 여러 가지가 있다. info() 함수를 이용하면 각 컬럼별로 누락 데이터를 확인할 수 있으며, isnull() 또는 notnull() 함수를 이용하여 누락 데이터 여부를 확인할 수 있다. 또한, 여러 함수와 isnull() 함수를 조합하여 누락 데이터의 개수나 비율을 구할 수도 있다.
2) 누락값 채우기(fillna)
fillna() 함수를 사용하여 누락값을 특정한 값으로 채울 수 있다. fillna 함수의 인자로 method를 지정할 수 있다. 누락값의 앞의 값으로 대치하고 싶은 경우는 ffill, 뒤에 있는 값으로 대치하고 싶은 경우는 bfill을 사용할 수 있다. 평균, 중앙값, 최소값, 최대값 등을 지정하여 사용할 수도 있다. 만약 이러한 방식이 아닌, 특정 값 0이나 임의의 값으로 대치하고 싶다면 method를 지정하지 않고 그 값을 입력해주면 된다.
데이터프레임.fillna(특정값, method=’ffill’,’bfill’)
3) 누락값 삭제(dropna)
누락값을 특정한 값으로 채우는 방법 외에도, 데이터를 정제하기 위해 누락값을 삭제하는 방식을 사용할 수 있다. 이때 사용되는 함수는 dropna()이다. 전체 데이터 중 누락값이 있는 행과 열을 선택하여 삭제하거나, 특정 행이나 열 전체에 누락값이 있는 경우나 하나라도 누락값이 있는 경우 삭제하는 옵션을 줄 수도 있으며, 정상값의 최소 갯수를 설정할 수도 있다. 또한, 특정 열에 대해서만 실행하는 옵션을 선택할 수도 있다.
데이터프레임.dropna( axis = 0 또는 1, how=’any’ 또는 ‘all’, thresh= 정상값의 갯수, subset=[열], inplace=True 또는 False)
3-3. 그외의 DataFrame 변경
1) 행 또는 열 삭제(drop)
행과 열을 삭제하는 방법은 해당 행과 열을 인덱싱하여 사용할 수 있거나, drop 함수를 이용하는 방법이 있다. 간단한 데이터의 삭제는 인덱싱과 슬라이싱을 통해서 해당 데이터를 제외한 나머지 데이터를 저장하는 방식으로 사용할 수 있다. 또한, drop 함수의 경우 특정 행 또는 열의 인덱스와 이름을 이용하여 삭제가 가능하다.
데이터프레임[ 유지할 행번호] / 데이터프레임[ [ 유지할 컬럼명 ] ]
데이터프레임[유지할 행번호][[유지할 컬럼명]]
데이터프레임.drop([삭제할 인덱스], axis=0)
데이터프레임.drop([삭제할 컬럼명], axis=1)
2) 열의 추가
열(Column)을 추가하는 방법은 새로 추가할 열(column)의 이름을 DataFrame 뒤에 대괄호( )를 이용하여 작성하고 해당 데이터를 할당하면 된다. 단, 주의할 점은 이러한 추가 방식은 꼭 해당 index를 맞추어야 한다는 것이다.
데이터프레임[’추가할 컬럼명’] = [추가할 데이터]
3) 중복 행 제거
중복 행을 찾는 방법은 duplicated() 함수를 사용하여 중복 여부를 확인할 수 있다. 모든 행을 검색하여 중복되는 행에 대해 True를 반환하고 중복되지 않는 행은 False를 반환한다. 이때, 삭제하려는 데이터의 기준을 설정할 수 있다. keep을 통해 남길 데이터를 선택할 수 있다. False를 선택하면 중복된 데이터를 모두 선택한다.
데이터프레임.duplicated([컬럼명], keep= ‘first’, ‘last’, False)
중복 행을 찾는 것 외에도, 중복 행을 삭제하는 drop_duplicates() 함수가 있어 중복 행에 대한 기준은 duplicated()와 같다.
데이터프레임.drop_duplicates([컬럼명], keep= ‘first’, ‘last’, False)
4. DataFrame의 병합
4-1. merge
pd.merge() 함수는 특정 행 또는 열을 기준으로 두 개의 DataFrame을 병합하는 함수다. merge를 사용하기 위해서는 공통된 행 또는 열이 필요다. 만약 공통으로 사용되는 행 또는 열이 있다면, 이 key를 기준으로 쉽게 두 개의 DataFrame을 병합할 수 있다. 이렇게 공통으로 사용되는 행 또는 열의 데이터를 "key"라고 하며, 이 key를 기준으로 데이터를 합칠 수 있다.
pd.merge(df1, df2, on=’기준열’, how= 병합 방식)


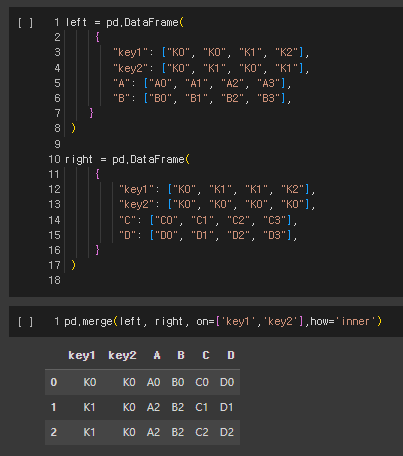
1) inner join
두개의 DataFrame의 key가 모두 존재하는 경우에만 병합하는 방식

2) outer join
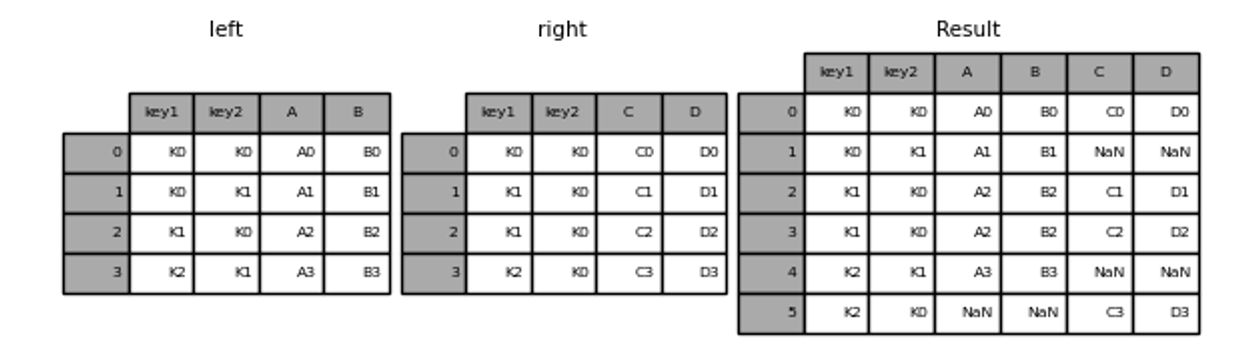
한쪽의 DataFrame에만 key가 존재해도 두DataFrame을 병합하는 방식

3) left join
왼쪽의 DataFrame의 key를 기준으로 병합하는 방식


4) right join
오른쪽의 DataFrame의 key를 기준으로 병합하는 방식


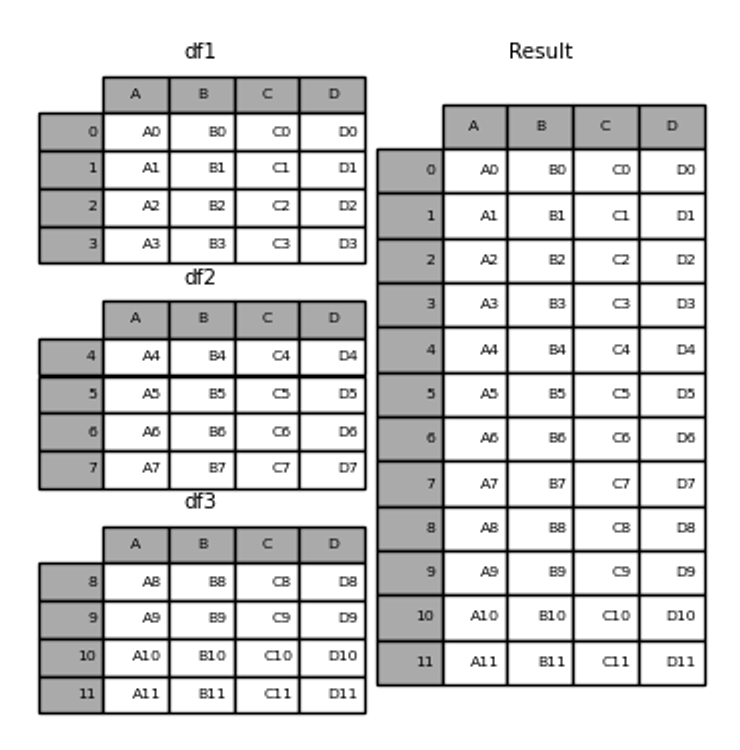
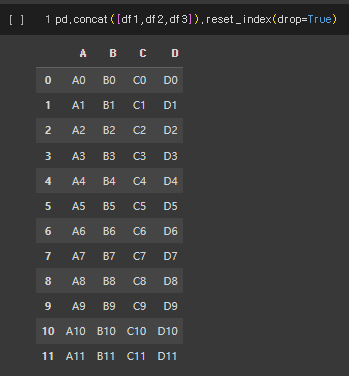
4-2. concat
concat은 두 개 이상의 DataFrame을 기준 열 없이 합성하는 방식을 말한다. key를 사용하지 않기 때문에 데이터를 단순히 합성하는 데 사용된다. 또한, axis를 설정하여 row 방향으로 추가할지 column 방향으로 추가할지 설정할 수 있다.
pd.concat([df1, df2, …], axis= 0 또는 1 , join= 병합 방식(inner 또는 outer))


5. DataFrame 조건식
5-1. 특정 조건에 맞는 데이터 추출
DataFrame에서는 특정 조건에 맞는 데이터를 추출하기 위해서 대괄호 [ ]를 사용한다. 인덱싱을 하는 것과 마찬가지로 대괄호 안에 조건식을 작성하면 해당 조건이 참인 경우에 해당하는 데이터만 추출할 수 있다.
데이터프레임[조건식]
5-2. 그룹을 활용한 데이터 추출
DataFrame의 특정 열을 그룹으로 지정하여 사용할 수 있다. 그룹을 설정하면 해당 그룹의 대표값이 반드시 필요하다. 그룹핑된 데이터의 합계, 평균, 갯수 등 다양한 값이 대표값이 될 수 있다.
데이터프레임.groupby([컬럼명, .. ]).대표값()
| 함수 | 내용 |
| count | 데이터의 개수 |
| sum | 합계 |
| mean | 평균 |
| median | 중앙값 |
| var,std | 분산, 표준편차 |
| min, max | 최소, 최대값 |
| unique, nunique | 고유값, 고유값 개수 |
| prod | 곱 |
| first, last | 첫째, 마지막값 |

댓글