1. Pandas
Pandas는 Python의 대표적인 데이터 처리 및 분석 라이브러리다. 특히, 1차원 배열(시리즈: Series)과 2차원 행렬(DataFrame)을 다루는 데 유용하며, 시계열 데이터를 분석하는 데 많이 사용된다.
1-1. 데이터를 빠르고 효율적으로 조작할 수 있는 DataFrame 객체
Pandas는 데이터를 빠르고 효율적으로 조작할 수 있는 DataFrame 객체를 제공한다. 이 객체는 메모리 기반의 데이터 구조로 데이터 처리가 빠르고 데이터의 요소에 직접 접근할 수 있다. DataFrame은 2차원 배열로 데이터를 구조화하고 처리하는 데 사용되며, 여러 유형의 데이터를 저장하고 조작하는 데 유용하다.



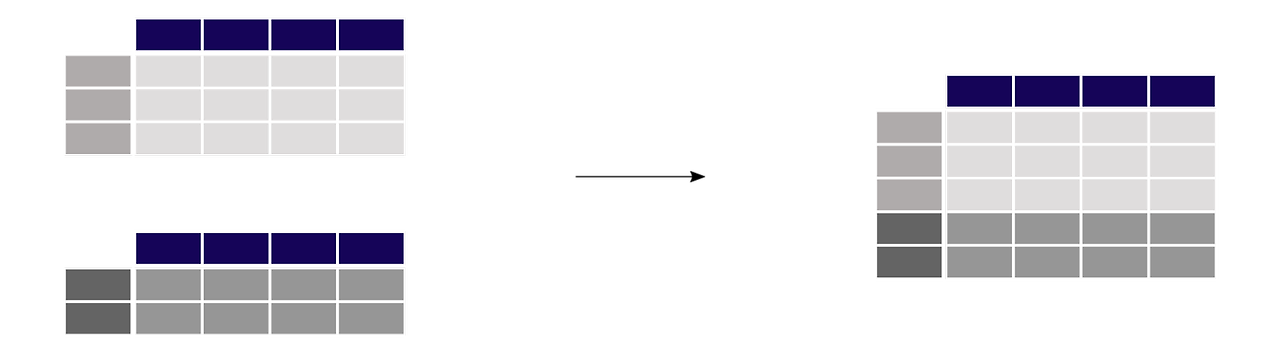
1-2. 유연한 데이터 조작과 데이터 집계
Pandas는 외부 데이터 (예: Excel, CSV, SQL, 텍스트 등)를 불러와 사용할 수 있다. 인덱싱과 슬라이싱을 자유롭게 사용할 수 있고, 데이터 그룹화, 결합, 병합 등이 쉽게 가능하여 데이터를 유연하게 조작할 수 있다. 누락된 값이나 이상값을 처리할 수 있으며, 다양한 통계 함수를 지원하여 데이터 분석을 수행하기 전에 데이터 전처리를 용이하게 할 수 있다.


1-3. 데이터 분석에 최적화된 기능과 다른 라이브러리와의 연결기능
Pandas는 데이터 분석에 필요한 기능과 도구를 제공한다. 날짜와 시간 데이터를 쉽게 조작할 수 있어 시계열 데이터 분석에 유용하며, 다른 파이썬 라이브러리인 Numpy, Tensorflow, Matplotlib 등과 호환되는 자료형을 사용하여 딥러닝, 시각화 등 다양한 분석 작업을 수행할 수 있다.
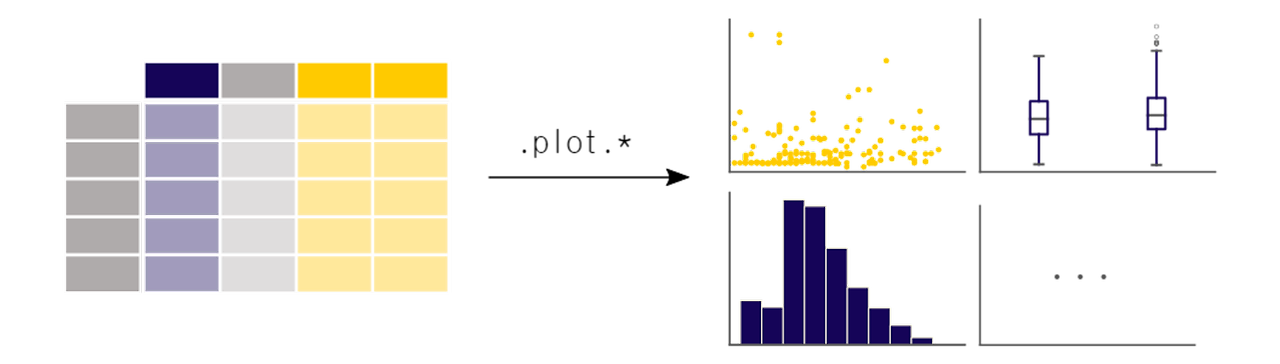
2. Pandas의 자료구조
2-1. 기본 자료형
|
object
|
string
|
문자열
|
|
int64
|
int
|
정수
|
|
float64
|
float
|
소수점을 가진 숫자
|
|
datetime64
|
datetime
|
파이썬 표준 라이브러리인 datetime이 반환하는 자료형
|
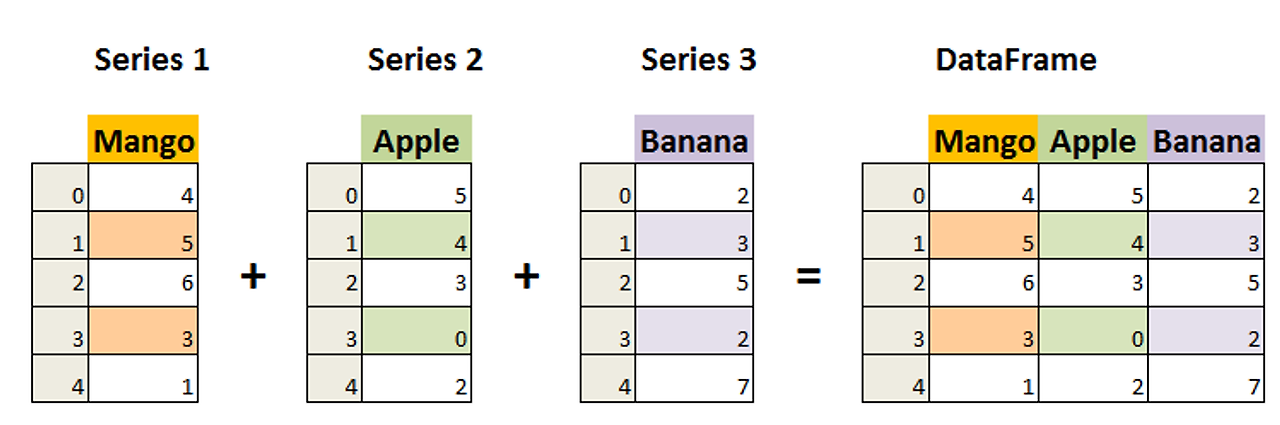
2-2. 시리즈(Series)
시리즈(Series)는 Pandas에서 제공하는 자료형으로, Numpy의 1차원 배열과 유사한 기능을 수행한다. 시리즈는 데이터 값에 인덱스(index)를 부여하여 각 데이터에 접근할 수 있고, 인덱싱과 슬라이싱을 통해 데이터를 추출할 수 있다.
시리즈는 일련의 데이터 값을 담는 컬렉션으로 생각할 수 있으며, 각 데이터 값은 고유한 인덱스로 식별된다. 이러한 인덱스는 데이터 값에 레이블을 부여하거나 데이터에 접근하기 위한 키 역할을 한다. 시리즈는 파이썬의 List와 유사한 구조이지만, 인덱스를 통해 데이터에 접근하는 데 강점을 가지고 있다.
또한, 시리즈를 이용하여 데이터프레임(DataFrame)을 생성할 수 있다. 데이터프레임은 행(Row)과 열(Column)로 구성된 2차원 테이블 형태의 데이터 구조다. 시리즈를 열로 갖는 데이터프레임을 생성하면, 각 시리즈의 인덱스가 열의 이름으로 사용되며, 열 단위로 데이터를 관리할 수 있다. 데이터프레임은 데이터 조작, 분석 및 시각화에 매우 유용한 자료구조로 활용된다.
시리즈와 데이터프레임은 Pandas에서 데이터 조작 및 분석을 위한 핵심 자료구조로 사용되며, 데이터의 처리와 분석 작업을 효율적으로 수행하는 데 도움을 준다.

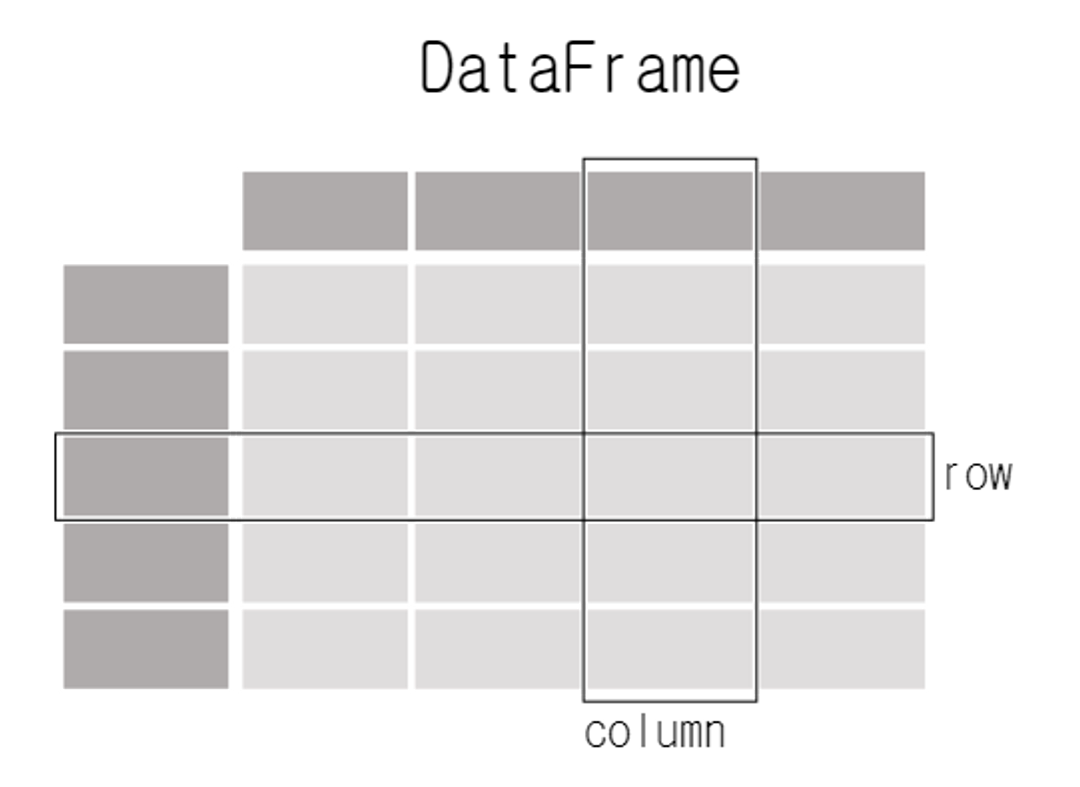
2-3. 데이터 프레임(DataFrame)
데이터프레임(DataFrame)은 Pandas의 핵심 자료구조 중 하나로, 2차원 테이블 형태의 데이터 구조다. 데이터프레임은 여러 개의 열(Column)로 구성되며, 각 열은 동일한 길이의 시리즈(Series)로 구성된다. 이러한 열들은 서로 다른 데이터 타입을 가질 수 있으며, 각 열은 해당 열의 이름으로 식별된다.
데이터프레임은 일반적으로 우리가 생각하는 테이블과 유사한 형태를 가지고 있어 행(Row)과 열(Column)로 인덱싱과 슬라이싱이 가능하다. 행을 기준으로 데이터를 조회하고 조작할 수 있으며, 열 단위로 데이터를 관리하고 변형할 수 있다. 또한, 데이터프레임은 다양한 데이터 조작 및 분석 기능을 제공하며, 외부 데이터를 불러와 데이터프레임으로 변환하여 사용할 수 있다.
데이터프레임은 데이터의 탐색, 정제, 가공, 변환, 분석 등 다양한 데이터 처리 작업에 유용하게 사용된다. 데이터프레임을 이용하여 데이터의 필터링, 그룹화, 정렬, 통계 분석, 시각화 등을 쉽게 수행할 수 있다. 또한, 데이터프레임은 다른 자료구조와의 호환성이 뛰어나기 때문에 다른 라이브러리와의 연동이 용이하며, 데이터 분석 및 머신러닝 작업에 널리 활용된다.
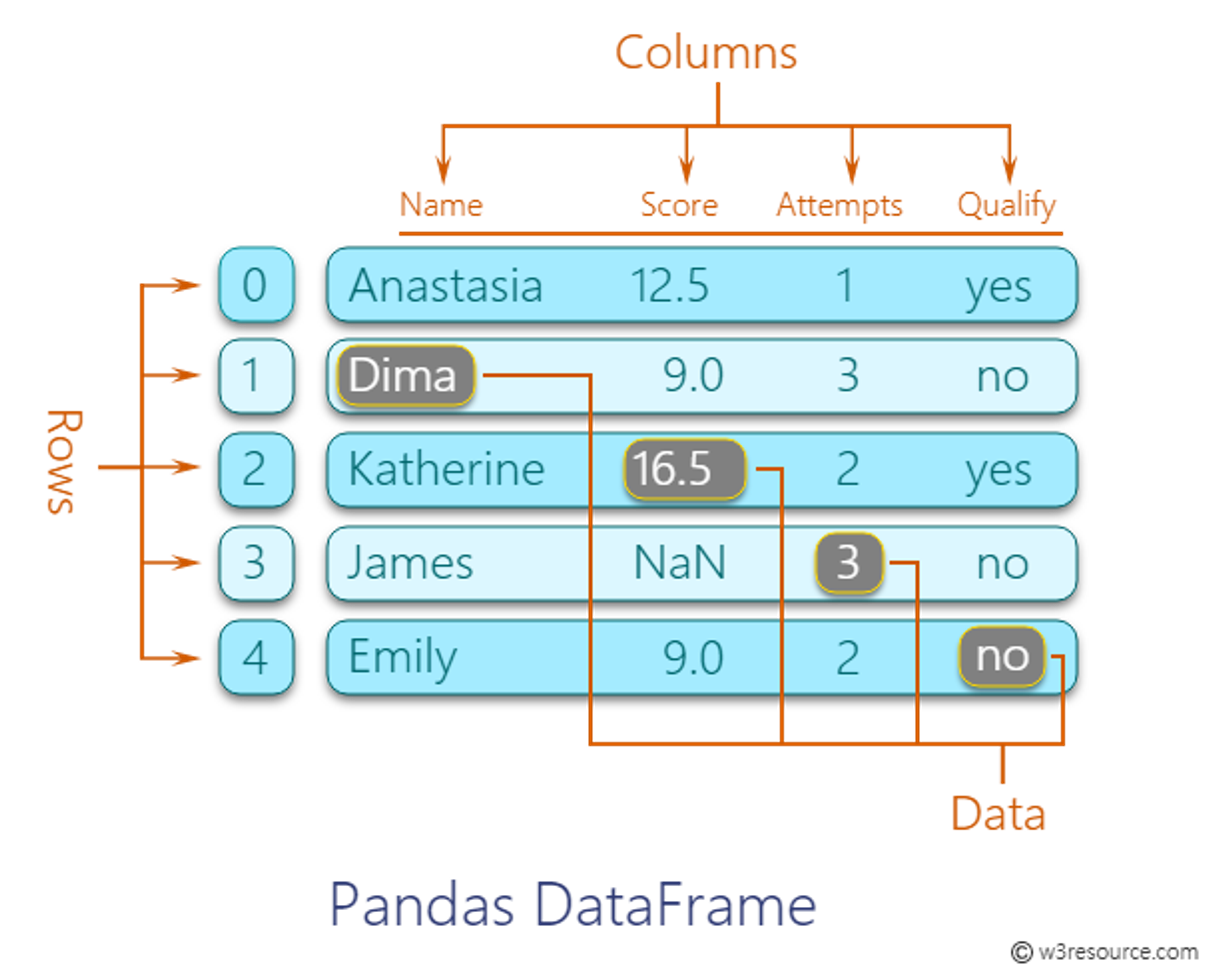
3. Pandas의 기능 활용
3-1. Pandas 기본
1) Pandas 불러오기
Pandas는 외부 라이브러리다. 사용하기 위해서는 import가 필요하다. 일반적으로 Pandas는 pd라는 별칭을 사용하여 활용한다. import pandas as pd
2) Series 생성
Pandas의 Series 함수를 사용하여 List, Dictionary, Tuple 또는 Numpy의 배열을 Series로 변환할 수 있다. Series는 1차원 배열 형태의 데이터를 가지는 군집형 자료구조이며, 파이썬의 List, Dictionary, Tuple 또는 Numpy의 배열을 Series로 변환하여 사용할 수 있다.
Series의 Index는 변경이 가능하고, Dictionary를 사용할 경우 Key가 Index로 활용된다. Index를 직접 지정하지 않으면 자동으로 0부터 시작하는 정수형 Index가 생성된다. Index는 데이터에 대한 고유한 식별자로 사용되며, 데이터에 접근하거나 조작할 때 유용하게 활용된다.
Series 함수를 사용하여 데이터를 Series로 변환할 때, 'S'가 대문자인 'Series'라는 점에 주의해야 한다. 예를 들어, List를 Series로 변환하려면 pd.Series() 함수를 사용하며, Dictionary를 Series로 변환하려면 Dictionary를 pd.Series() 함수의 인자로 전달한다.
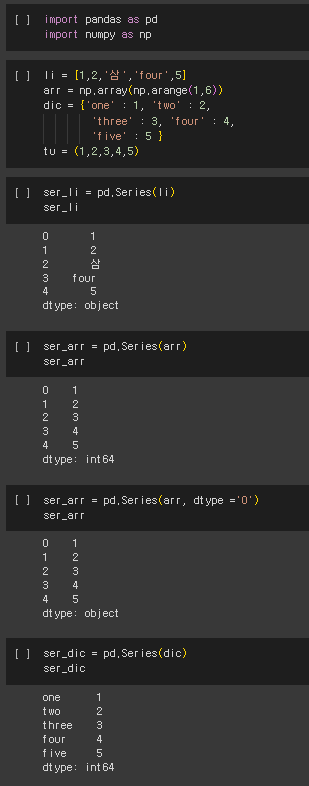
3) DataFrame 생성
Pandas의 DataFrame 함수를 사용하여 DataFrame을 생성할 수 있다. DataFrame은 행(Row)과 열(Column)을 갖는 2차원 배열 구조를 가지며, Python에서 일반적으로 DataFrame을 생성할 때는 Dictionary를 사용하는 경우가 많다.
DataFrame을 생성할 때 Dictionary를 사용하면 각 Key-Value 쌍이 열(Column)로 구성되어 보기 편하고 쉽게 인덱싱과 슬라이싱이 가능하다. Dictionary의 Key는 DataFrame의 열(Column) 이름으로 사용되며, Value는 해당 열(Column)에 대한 데이터 값으로 사용된다. 따라서 Dictionary의 Key는 문자열 형태로 지정하는 것이 일반적이다. DataFrame을 생성한 후에는 인덱싱과 슬라이싱을 통해 데이터에 접근하고 조작할 수 있다. 열(Column) 이름을 사용하여 열(Column) 단위로 데이터를 조회하거나, 행(Row) 인덱스를 사용하여 특정 행(Row)의 데이터를 조회할 수 있다.
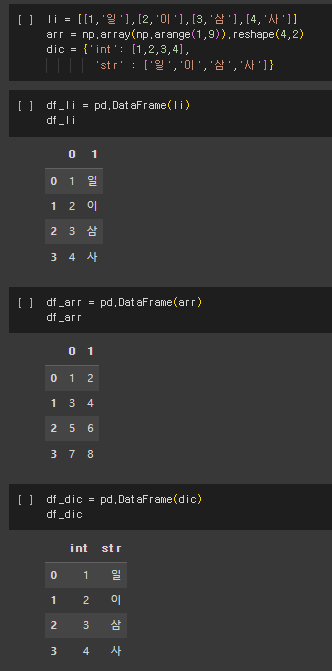
4) 파일 불러오기
Pandas는 다양한 파일 형식을 불러와서 사용할 수 있는 기능을 제공한다. Excel, CSV, JSON, SQL 등 다양한 데이터 형식을 처리할 수 있으며, 이러한 데이터를 쉽게 DataFrame으로 변환하여 사용할 수 있다.
Pandas는 read_excel(), read_csv(), read_json(), read_sql() 등의 함수를 제공하여 각각의 파일 형식을 불러올 수 있습니다. 이러한 함수를 사용하면 파일로부터 데이터를 읽어와서 DataFrame으로 변환할 수 있습니다.
또한, 데이터를 불러올 때 필요한 행(Row)과 열(Column)을 지정하는 기능도 제공된다. 예를 들어, 엑셀 파일의 특정 시트를 불러올 때 행과 열의 범위를 지정하여 원하는 데이터를 선택적으로 가져올 수 있다. 이를 통해 대용량의 데이터를 효율적으로 처리할 수 있다.

3-2. 데이터 핸들링(Data Handling)
1) Index와 Column명 변경
Pandas에서는 Index와 Column의 이름을 변경하는 기능을 제공한다.
Series의 Index를 변경하기 위해서는 rename() 함수를 사용할 수 있다. 이 함수에는 변경하고자 하는 기존 Index와 변경할 새로운 Index가 매핑된 딕셔너리 형태의 인자를 전달하고, 필요에 따라 기존 Series를 직접 변경할 것인지를 설정할 수 있다. 또한, 직접 Index에 값을 대입하여 변경할 수도 있다.
- Series의 Index를 변경하는 방법:
시리즈.rename(dictionary, inplace= True/False)
시리즈.index = 변경할 값 목록
또한, Index를 0부터 순차적으로 증가하는 정수로 변경하려면 reset_index() 함수를 사용할 수 있다. 이 함수를 사용하면 기존 Index가 새로운 Column으로 추가되는데, 필요에 따라 기존 Index를 버리고 새로운 Index를 초기화할 수 있다.
- Series의 Index를 재설정하는 방법:
시리즈.reset_index(inplace=True/False ,drop = True/False)
DataFrame도 Series에서 사용된 방식과 동일한 방법으로 Index와 Column의 이름을 변경할 수 있다. rename() 함수를 사용하거나 직접 값을 대입하여 변경할 수 있다. 또한, reset_index() 함수를 사용하여 Index를 재설정할 수도 있다.
- DataFrame의 Index와 Column을 변경하는 방법:
데이터프레임.rename(index= dictionary, columns= dictionary, inplace =True/False)
데이터프레임.index = 변경할 값 목록
데이터프레임.columns = 변경할 값 목록
데이터프레임.reset_index(inplace=True/False ,drop = True/False )
- DataFrame에서 특정 열을 인덱스로 설정하는 방법:
데이터프레임.set_index = (인덱스로 설정할 열번호 , inplace=True/False ,drop = True/False , append = True/False )
데이터프레임은 sort_index() 함수를 사용하여 인덱스를 정렬하고, sort_values() 함수를 사용하여 특정 Column을 기준으로 정렬할 수도 있다.
- 데이터프레임의 정렬 방법:
데이터프레임.sort_index( ascending=[True/False])
데이터프레임.sort_values(by= [기준 Column], ascending=[True/False])
2) 데이터 조회
Pandas에서는 DataFrame 또는 Series의 데이터가 열 방향으로 축적되기 때문에 데이터의 전체를 확인하기 어려운 경우가 많다. 이럴 때는 데이터의 일부를 쉽게 확인하기 위해 head() 함수와 tail() 함수를 사용할 수 있다.
head() 함수는 DataFrame 또는 Series의 첫 번째 행부터 n개의 데이터를 반환하는 함수다. 이를 통해 데이터의 첫 부분을 빠르게 확인할 수 있다.
tail() 함수는 DataFrame 또는 Series의 마지막 행부터 n개의 데이터를 반환하는 함수다. 이를 통해 데이터의 마지막 부분을 빠르게 확인할 수 있다.

댓글