군집분석(Cluster Analysis)은 비슷한 특성을 가진 데이터들을 묶어주는 기술이다. 이를 통해 데이터 간의 유사성을 파악하고, 데이터를 분류하거나 축소하는 등의 다양한 분석에 활용된다. 군집분석에는 계층적 군집분석과 비계층적 군집분석이 있다. 계층적 군집분석은 데이터 간의 거리나 비유사도를 계산하여 군집을 형성한다. 이러한 계층적 군집분석은 일종의 트리 구조로 표현된다. 루트 노드는 모든 데이터를 포함하고, 하위 노드는 더 작은 군집을 의미한다. 비계층적 군집분석은 군집의 개수를 미리 지정하고 군집을 형성한다.
군집분석은 비지도학습(Unsupervised Learning)의 일종으로, 레이블이 없는(unlabeled) 데이터를 다루는 경우에 유용하다. 이는 레이블이 없는 상태에서 데이터들의 패턴이나 특성을 파악하는 데 사용된다. 군집분석은 레이블된 데이터를 다루는 지도학습(Supervised Learning)과 대조된다.
1. 군집분석 종류
1-1. DBSCAN
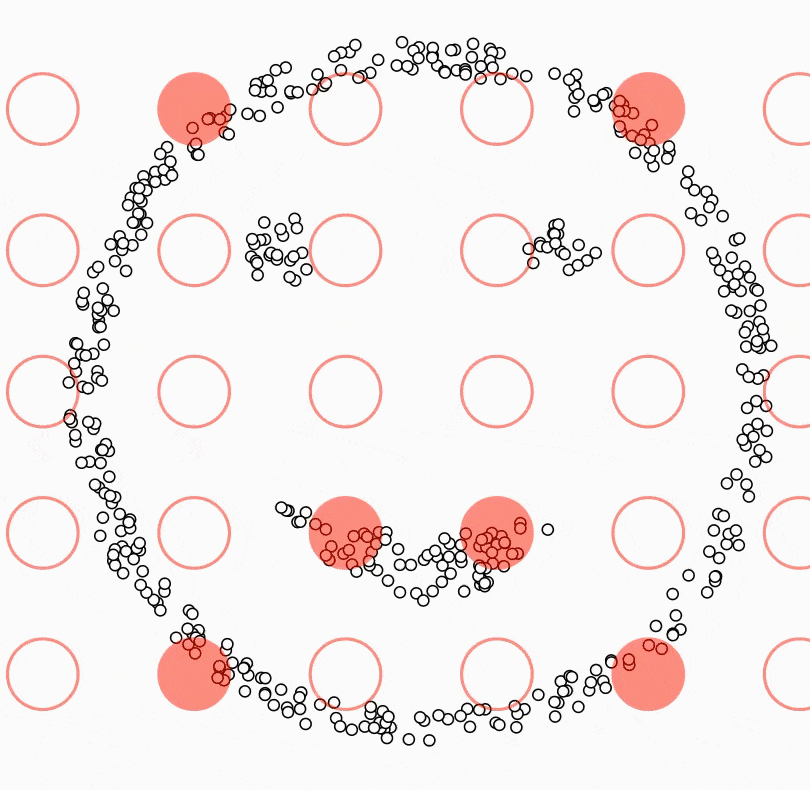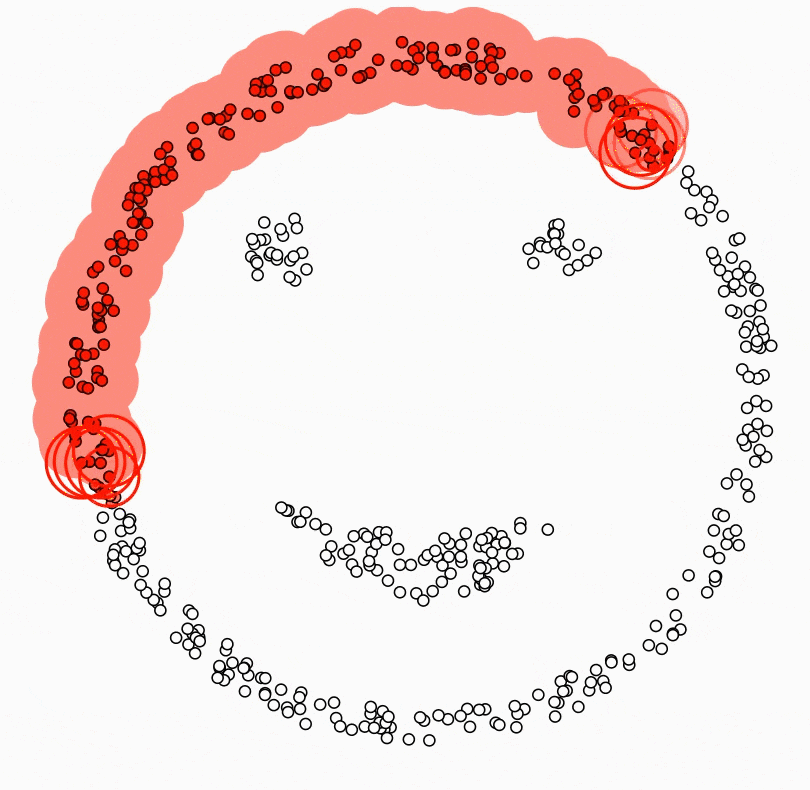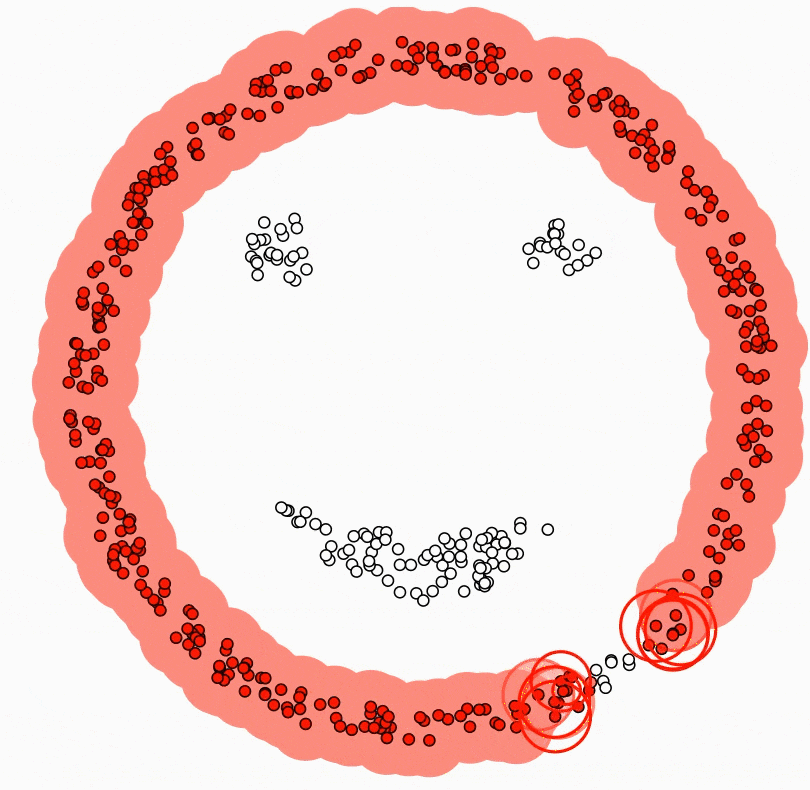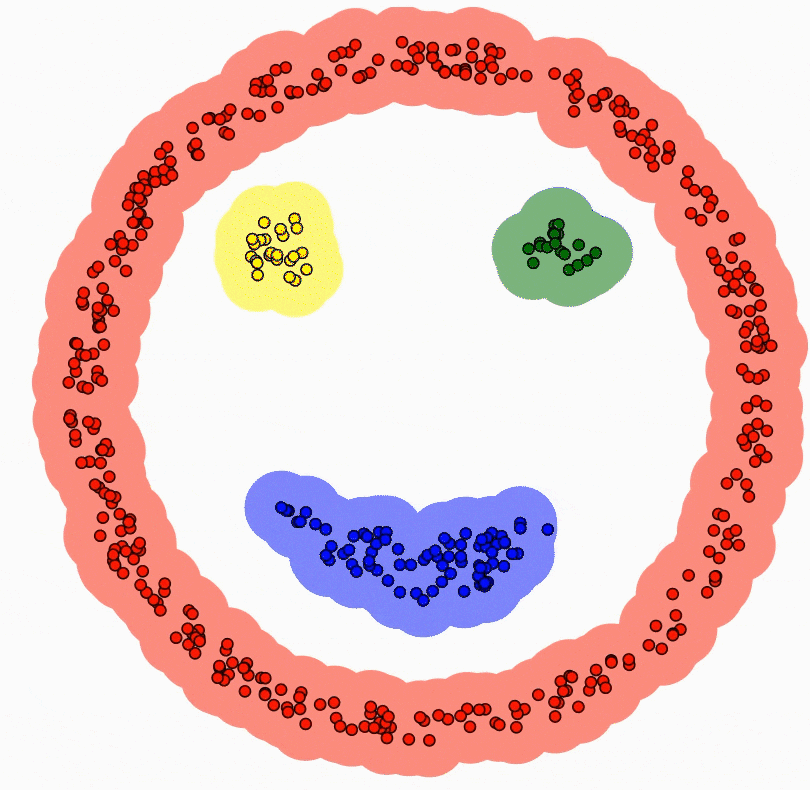
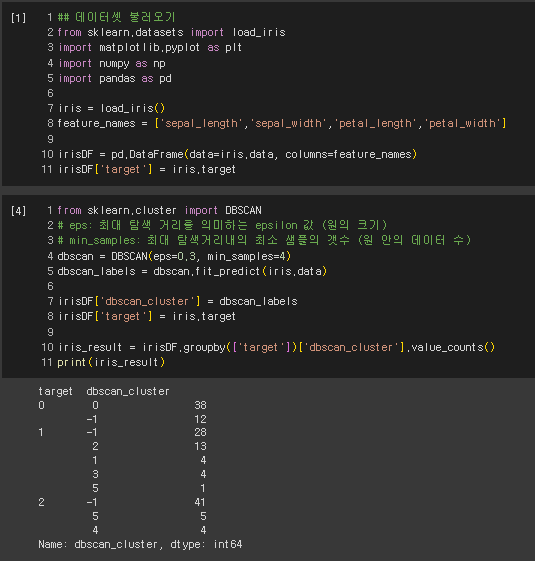
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)는 기계 학습에서 널리 사용되는 군집화 알고리즘이다. 지정된 반경과 최소 데이터 포인트 수에 기반하여 서로 가까운 데이터 포인트를 그룹화하는 데 사용된다.
DBSCAN은 특히 많은 노이즈가 있는 데이터나 군집 수가 불명확한 경우에 유용하다. 또한 일부 다른 군집화 알고리즘은 클러스터가 구 형이거나 특정 모양이어야 하지만, DBSCAN은 불규칙한 모양과 크기의 데이터를 처리할 수 있다.
DBSCAN의 주요 장점 중 하나는 군집 수를 미리 지정하지 않아도 된다는 것이다.

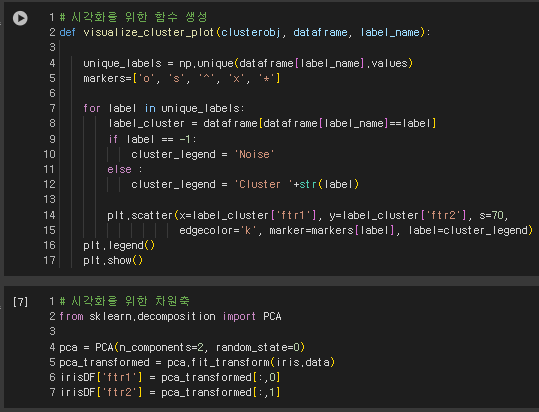


1-2. K-means 클러스터링
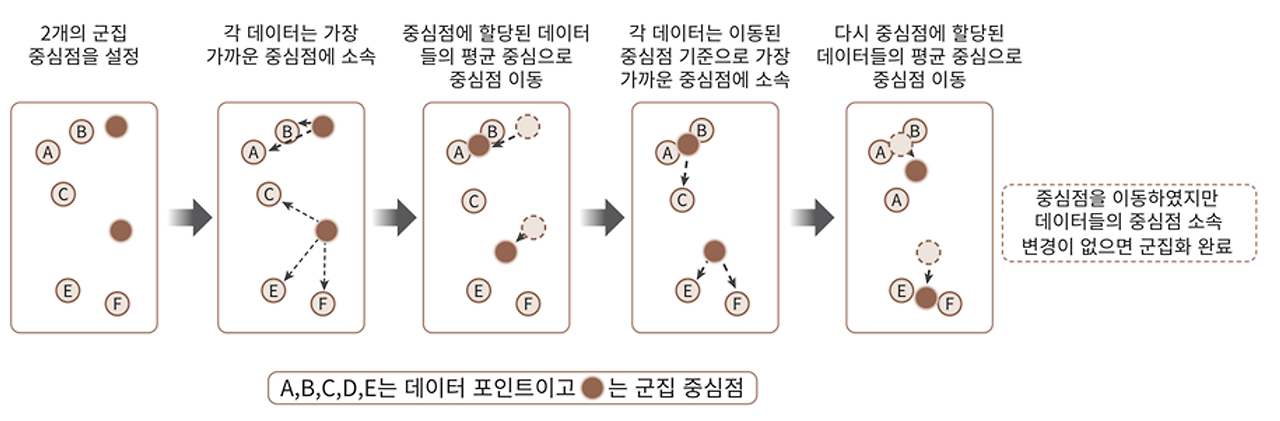
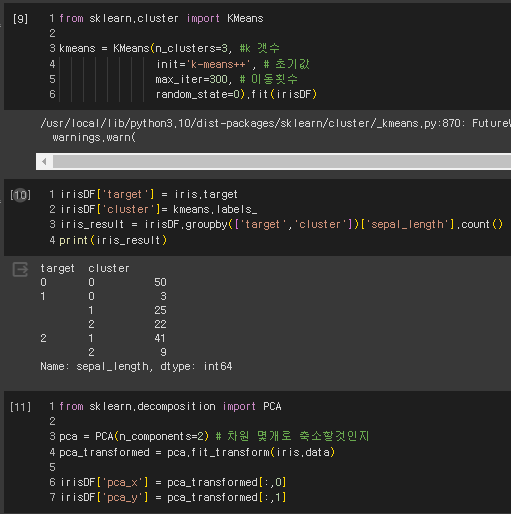
K-means 클러스터링은 비지도 학습의 대표적인 방법 중 하나이다. 이 방법은 주어진 데이터를 지정된 수의 클러스터로 그룹화하여 데이터 간의 유사성을 기반으로 패턴을 발견하는 데 사용된다.
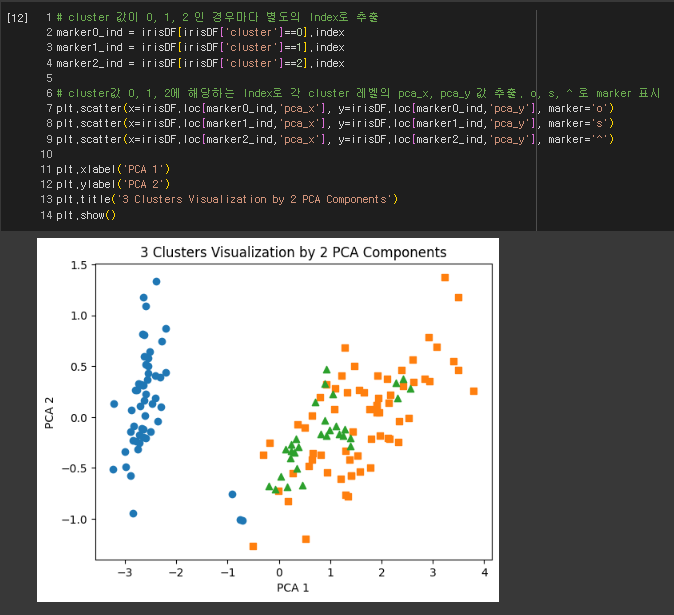
2. 군집분석 평가
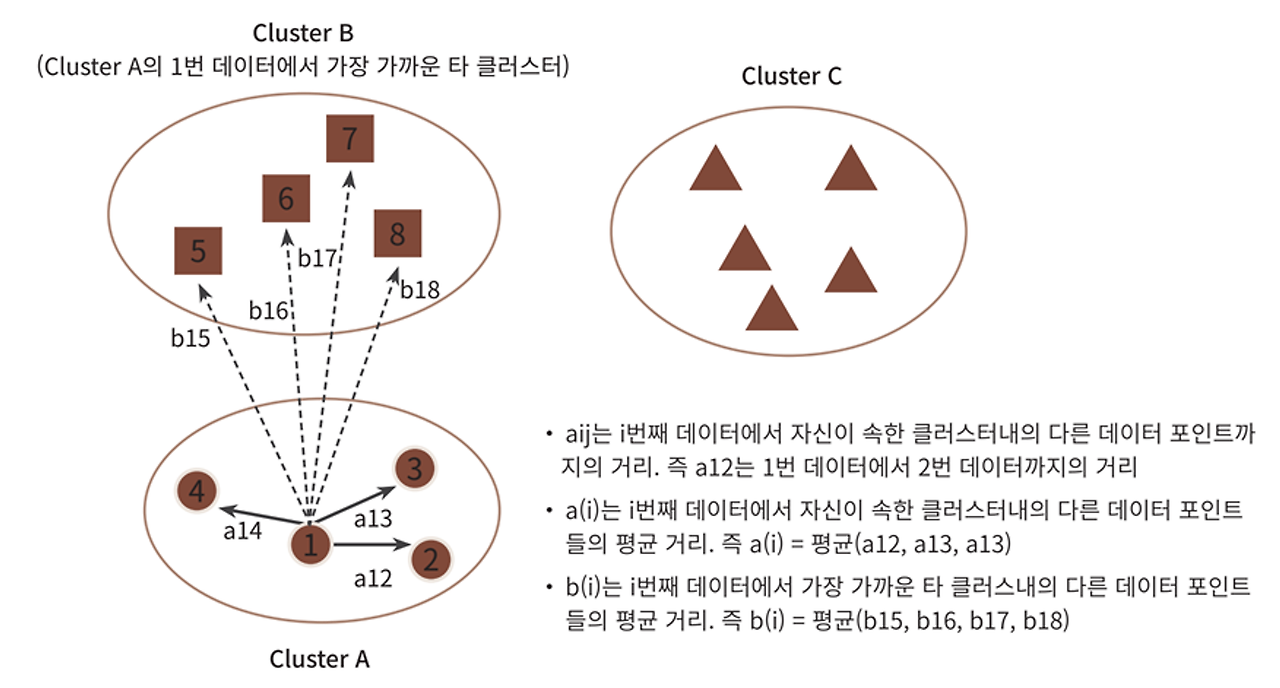
2-1. 실루엣계수
실루엣 계수(silhouette coefficient)는 군집내 데이터가 얼마나 밀접하게 모여있고, 군집 간 데이터가 얼마나 분리되어 있는지를 나타내는 지표이다. 실루엣 계수는 -1에서 1사이의 값을 가지며, 1에 가까울수록 군집화가 잘 되었다는 것을 의미한다. 즉, 실루엣 계수가 높을수록 데이터가 잘 군집화되어 있다는 것을 나타내며, 이를 통해 군집화 결과를 평가할 수 있다.
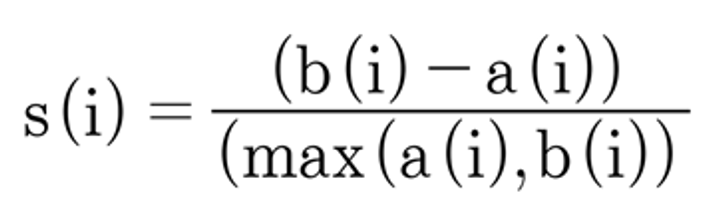

댓글