1. Crawling
크롤링이란 조직적 / 자동화된 방법으로 데이터를 탐색 / 수집하는것을 말한다. 파이썬과 파이썬의 라이브러리를 활용하면 비교적 쉽게 원하는 정보를 수집하고 데이터를 모을 수 있다.
1-1. HTTP
HTTP란 Hyper Text Transfer protocol의 약자로 인터넷 상에서 HTML 문서의 정보를 주고받을 수 있도록 만든 프로토콜(Protocol, 전송규약)이다. 웹 사이트에 접속하는 디바이스를 클라이언트(Client)라고 하고 웹 사이트를 운영하는 시스템을 서버(Server)라고 한다. 클라이언트는 인터넷을 통해서 서버에 HTTP형식으로 원하는 정보를 요청(Request)하고 서버는 이러한 요청을 HTTP형식으로 응답(Response)해 HTML(Hyper Text Markup Language) 파일을 보내주는 방식으로 통신한다. 이러한 HTML 파일을 웹 브라우저가 해석해 우리가 알고있는 웹페이지형식으로 볼 수 있도록 해준다.

1) Request
사용자가 원하는 파일 또는 리소스의 위치와 브라우저에 관한 정보를 포함하고 있다.
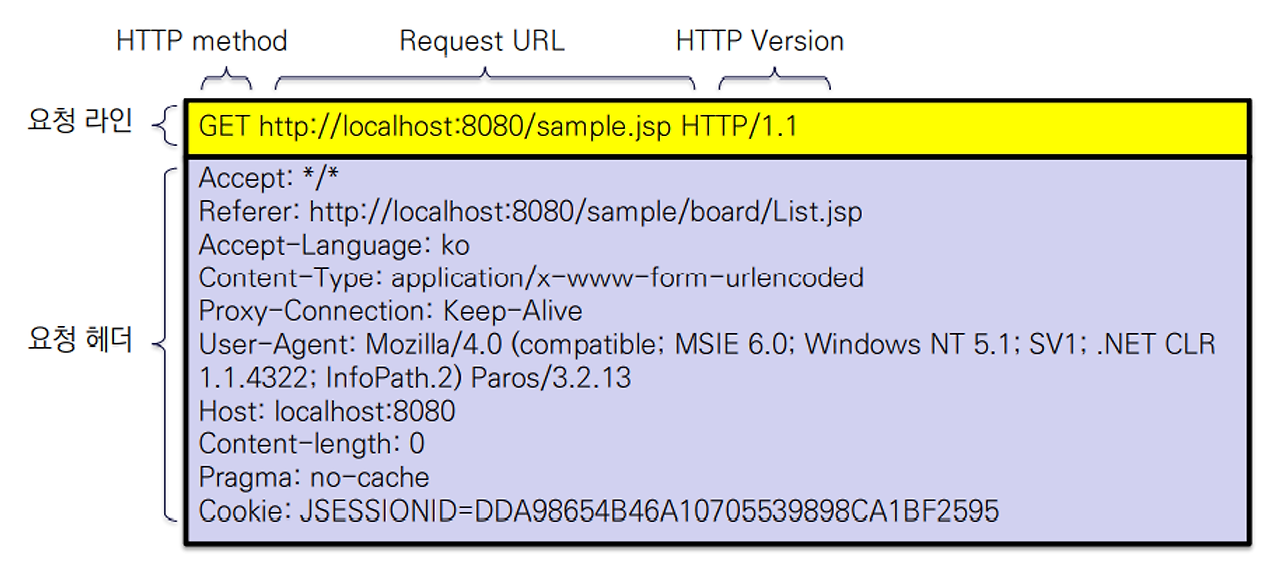
2) Response
응답 객체, 텍스트, 그래픽등의 정보를 포함 할 수 있다.

1-2. Pasing
웹페이지에서 원하는 데이터를 추출하여 가공하기 쉬운형태로 바꾸는 것을 파싱(Parsing)이라 한다. Response를 통해서 받은 결과물인 HTML, Json, XML등의 파일은 우리가 원하는데로 변경하거나 취급하기 어렵기 때문에 파서(Paser)라는 프로그램을 통해서 다루기 쉬운 형태로 변경하게 된다.
파이썬에 대표적인 Paser로는 BeautifulSoup이라는 라이브러리를 통해서 HTML 문서를 파싱할 수 있다.
파이썬에서 크롤링을 하기위해서는 먼저 데이터 통신을 위한 requests나 urllib 라이브러리를 가져와 우리가 원하는 웹 페이지에 접속하여 원하는 정보를 추출한다.
그뒤에 BeautifulSoup 라이브러리를 통해서 불필요한 요소를 제거하고 필요한 정보들을 가져오는 작업을 진행할 수 있다.
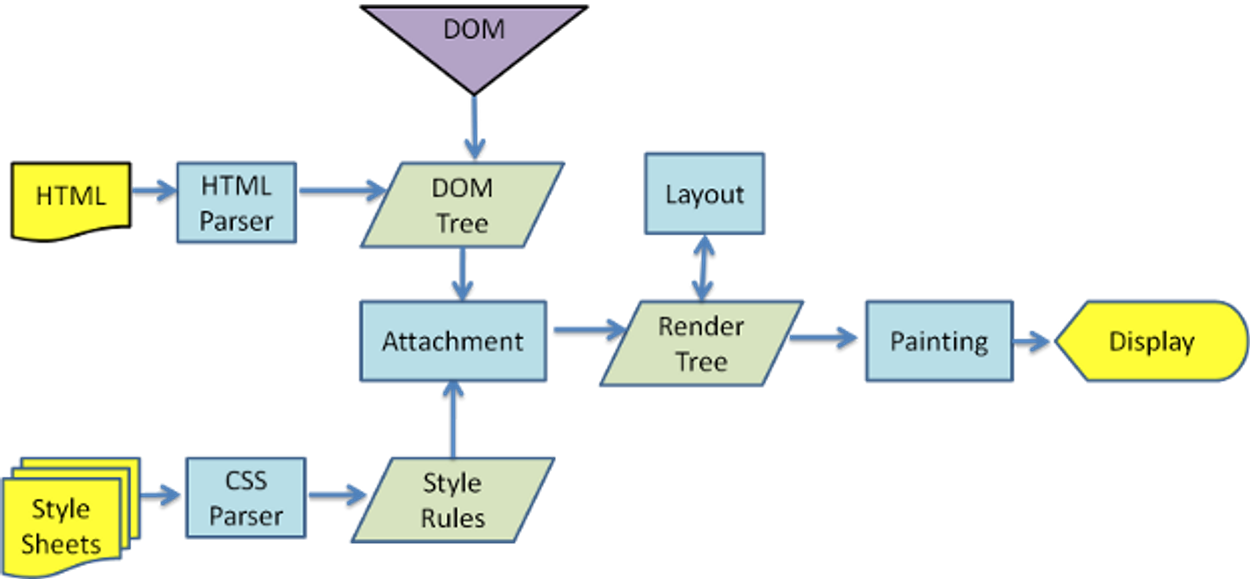
1-3. 주의사항
robots.txt는 웹 크롤러와 같은 봇 (Bot)들의 접근을 제어하기 위해 1994년 6월에 제정된 로봇 배제 표준이다. 누구에게 페이지의 접근 권한을 허락하며, 금지하는지에 대한 정보가 텍스트 파일에 기록되어 있다.

1) User-agent : 규칙적용 대상 (* : 모두에게 적용)
2) Disallow : 금지 페이지 ( / : 전체 페이지)
3) Allow : 허용 페이지 ( /$ : 루트 페이지)
데이터를 수집하는 것은 불법이 아니며, 어떻게 사용하느냐에 따라 법적문제가 발생할 수 있다.
이외에 짧은시간 웹서버를 지나치게 많이 접속하여 웹서버에 의한 공격으로 인식되어 접속이 차단될 수 있다. 이러한 경우에는 시도횟수를 지정하거나 시도중 time.sleep을 사용해 회피하기도 한다.
그리고 크롤링과 관련없이 저작권 법에 대한 법적 문제가 발생 할 수 있음으로 이러한 크롤링 외적인 문제에 대한 책임은 반드시 조심해야한다.
2. BeutifulSoup
BeautifulSoup는 HTML과 XML 문서를 파싱하기위한 파이썬 패키지이다. 웹 스크래핑에 유용한 HTML에서 데이터를 추출하는 데 사용할 수 있는 구문 분석 된 페이지에 대한 구문 분석 트리를 생성한다.
!pip install bs4
from bs4 import BeautifulSoup
soup = BeautifulSoup( 파싱할 데이터, “html.parser”)
1) BeutifulSoup은 가장 일반적으로 사용되는 CSS 선택자를 지원한다.
2) BeutifulSoup의 Selector API는 select()와 select_one, find()등이 있다.
3) soup.select("CSS선택자") : CSS 선택자에 해당하는 모든 요소를 반환한다.
4) soup.select_one("CSS선택자") : CSS 선택자에 맞는 오직 첫 번째 태그 요소만 반환한다.
2-1. CSS 선택자
1) CSS(Cascading Style Sheet)
CSS는 문서의 콘텐츠와 레이아웃, 글꼴 및 시각적 요소들로 표현되는 문서의 외관(디자인)을 분리하기 위한 목적으로 만들어졌다.
2) CSS 선택자
CSS를 이용해서 HTML 문서에 시각적 요소를 부여할 때 문서 내의 어느 요소에 부여할지를 결정하기 위해 사용하는 것으로 CSS 선택자(Selector)는 HTML 문서의 태그 이름, class 속성, id 속성 등을 이용해서 작성할 수 있다.
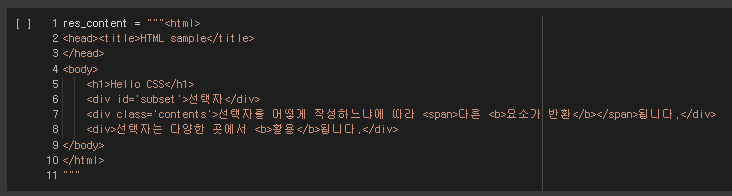
3) 태그 선택자("element")
태그 선택자는 일반적으로 스타일 정의하고 싶은 html 태그 이름을 사용 요소 안의 텍스트는 text, 태그이름은 name 그리고 태그의 속성들은 attrs를 이용해 조회할 수 있다.
soup.select("태그명")
4) 다중(그룹)선택자("selector1, selector2, selectorN")
선택자를 ","(comma)로 분리하여 선언하면 여러 개 선택자 적용할 수 있다.
soup.select("태그명1, 태그명2")

5) 내포 선택자("ancestor descendant")
요소가 내포 관계가 있을 때 적용시키기 위한 선택자. 선택자와 선택자 사이를 공백으로 띄우고 나열할 수 있다.
soup.select("상위태그명(공백)하위태그명")

6) 자식 선택자("parent>child")
선택자들 사이에 >를 입력하며 반드시 부모자식간의 관계에만 스타일이 적용되도록 함. 두 단계 이상 건너뛴 관계에서는 자식 선택자가 작동하지 않는다.
soup.select("부모태그 > 자식태그")

7) 클래스(class) 선택자(".class")
HTML 문서에서 class 속성의 값과 일치하는 요소를 선택한다. 선택자 이름 앞에 "."을 이용하여 선언한다.
soup.select("태그 . 클래스명")

8) 아이디(id) 선택자 ("#id")
HTML 문서에서 id 속성의 값과 일치하는 요소를 선택 id 선택자는 #으로 정의한다.
soup.select_one("#id명")

9) 속성 선택자 [name="value"]
특정한 속성을 갖는 요소만 선택. 속성 선택자는 대괄호( [ ] )사이에 속성의 이름과 값을 지정한다.
soup.select_one("[id=subject]")
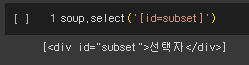
3. Requests
Requests란 파이썬에서 HTTP 요청을 만들기 위해 사용되는 표준 모듈이다.
3-1. requests 모듈의 활용
1) 가장 일반적인 HTTP 메소드를 사용하여 요청하기
2) 쿼리 문자열 및 메시지 본문을 사용하여 사용자의 요청과 데이터를 변경하기
3) 요청 및 응답에서 데이터 검사하기
4) 인증 된 요청 만들기
5) 응용 프로그램이 백업 또는 속도 저하를 막을 수 있도록 요청을 구성하기

3-2. GET
get은 HTTP 요청(Request) 방식 중 하나이다. requests.get(URL)을 통해서 지정된 리소스에서 데이터를 가져오고 response 객체를 생성하게 된다.
requests.get(URL)
1) status_code: 응답 객체의 상태 코드

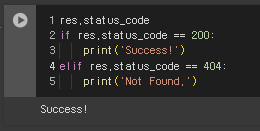
2) text: 응답결과 확인
응답 내용의 인코딩된 텍스트를 보기위해서 사용한다.
response.text
response.content
3) Encoding : 인코딩 지정
text 속성에 액세스할 때 문자열 인코딩을 지정할 수 있다. 지정하지 않을 경우 내부적으로 추론하여 자동 지정된다.
response.encoding = 'utf-8'
response.text
4) 응답처리 자동 인코딩 함수 생성

4. 웹 크롤링
4-1. 네이버에서 환율정보 가져오기



댓글