1. 빅데이터의 수집 개요
1-1. 빅데이터 생성
1) 데이터 자료와 정보
데이터는 관찰 및 측정을 통하여 획득할 수 있고, 가공되지 않은 상태이며, 단순한 사실이나 결과이다. 반면, 정보는 데이터를 가공하여 얻은 실질적인 결과이며, 의사결정에 기여하 는 형태이다.
| 데이터 Data |
관찰 및 측정을 통한 획득 |
| 가공되지 않은 상태 | |
| 단순한 사실이나 결과 |
| 정보 Information |
데이터를 가공하여 얻은 결과 |
| 의사결정에 기여 |
2) 데이터의 존재론적 특징에 따른 구분
데이터는 존재론적 관점에서 볼 때 정량적 데이터, 정성적 데이터로 구분할 수 있다. 정량적 데이터는 계량 가능한 형태의 데이터이며, 정형, 비정형의 형태를 가지고 있다. 반면, 정적 데이터는 추상적 형태이며, 비정형 데이터의 형태를 가지고 있다.
| 정량적 데이터 Quantitative Data |
언어, 문자 등 계량 가능 형태 |
| 정형·비정형 데이터 형태 | |
| 정성적 데이터 Qualitative Data |
언어, 개념 등 추상적 형태 |
| 비정형 데이터 형태 |
3) 데이터의 구성에 따른 구분
데이터는 데이터의 구성에 따라 정형 데이터, 비정형 데이터, 반정형 데이터로 구분할 수 있다. 정형 데이터는 사전에 정의된 데이터의 모델이 존재한다. 한편, 비정형 데이터는 사전 정의된 데이터 모델이나 데이터 해석 방법론이 미약한 특징을 지니고 있다. 반정형 데이터는 정형 데이터와 비정형 데이터의 양쪽 모두의 특성을 일부 지니고 있는 데이터의 형태이다.
| 정형 데이터 Structured Data |
사전 정의된 데이터 모델 존재 |
| 최적화 된 자료구조 적용 가능 | |
| 예) 스프레드시트, DBMS | |
| 비정형 데이터 Unstructured Data |
사전 정의된 데이터 모델이나 데이터의 해석 방법론이 미약 |
| 예) 멀티미디어 콘텐츠, SNS | |
| 반정형 데이터 Semi-structured Data |
정형-비정형 데이터의 중간 |
| 예) HTML, XML, JSON, 로그 |
4) 데이터의 구성에 따른 유용성
빅데이터는 수집 난이도, 구성 복잡도, 잠재적 가치에 따라 그 유용성이 달라진다. 정형 데이터보다 비정형 데이터의 수집 난이도가 높으며, 복잡도가 높고, 한편, 잠재적 가치 또한 비정형 데이터 쪽이 높다. 따라서 빅데이터에서는 앞으로 비정형 데이터의 취급 방법론이 대두될 것으로 예상된다.

1-2. 빅데이터의 수집
빅데이터 수집은 시스템의 내외부에서 주기성을 가지고 필요한 형태로 데이터를 모으는 작업을 뜻한다. 빅데이터 수집을 통하여 유용한 데이터를 선택함으로써 산출물의 품질을 향상 시킬 수 있으며, 최적의 방법론을 선택함으로써 수집 안정성을 극대화할 수 있고, 수집 소요 비용을 최소화할 수도 있다.

2. 빅데이터의 수집 방법론
2-1. 빅데이터 수집 절차 설계
빅데이터는 수집 데이터를 선정하고, 세부 계획을 수립하며, 테스트 수집을 진행하고, 본격적인 수집을 진행하는 절차를 가진다.
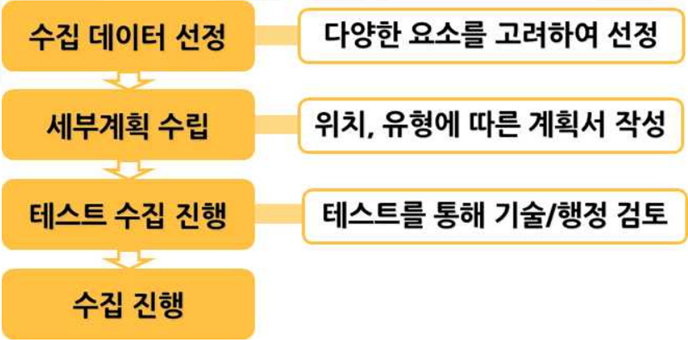
수집 데이터 선정 과정은 가능성, 정확성, 난이도, 비용, 보안 등의 관점에서 검증이 필요하다. 수집 데이터의 선정 가능성은 불가능 또는 주기의 통제 가능 여부를 확인하는 것이다. 수집 데이터의 선정 정확성은 내용의 정확성, 정밀성, 그리고 사전처리 필요 여부를 확인한다. 수집 데이터 선정의 난이도는 비용, 수집 과정에 따른 대안을 고려하는 것이다. 수집 데이터 선정의 비용은 데이터 획득에 필요한 직접적인 비용이 어느 정도인지 검토하는 것이다. 마지막으로 수집 데이터 선정의 보안성은 데이터 선정 대상의 개인정보 관련 문제 발생 여부를 검토하는 것이다.

수집 데이터를 선정한 이후에는 수집의 세부 계획을 수립하는 것이 필요하다. 데이터의 위치와 유형을 파악하고, 수집 계획서를 작성하는 것이 필요하다.

수집에 앞서 테스트 수집의 진행이 필요하다. 테스트 수집 과정 중 기술적인 검토와 행정적인 검토를 수행하게 된다. 기술적으로는 데이터 누락, 원본 데이터와의 전수 비교, 정확성 측정 등의 과정이 필요하다. 행정적으로는 보안성, 저작권 관련 문제, 트래픽 발생량 등의 고려가 필요하다.

2-2. 빅데이터 수집 계획서
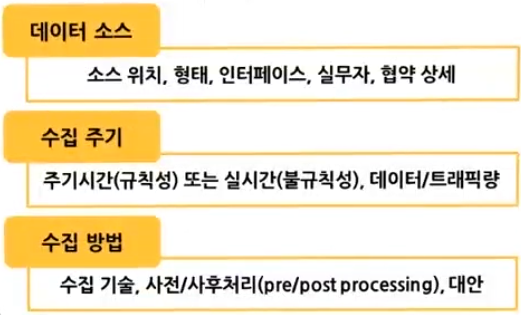
빅데이터를 수집하기에 앞서, 빅데이터 수집 계획서를 작성하는 것이 필요하다. 빅데이터 수집 계획서에는 데이터 소스(원천), 수집 주기, 수집 방법 등이 정확히 기술되어 있어야 한다.
2-3. 빅데이터 수집 도구
빅데이터의 수집에는 다양한 도구를 활용할 수 있다. 이러한 도구는 인적 자원, 자동화 도구로 구분할 수 있다. 인적 자원을 활용할 경우 인적 자원 비용이 발생하며, 오해석, 오차 등의 문제에 대한 대비책을 마련하여야 한다. 반면, 자동화 도구 사용할 경우, 대부분의 과정에서 인간의 개입이 거의 없으며, 인적 자원 비용을 최소화하는 것이 가능하며, 원천 형태에 따라 적용이 불가능할 수 있으므로 주의하여야 한다.

2-4. 빅데이터 자동화 수집 기술
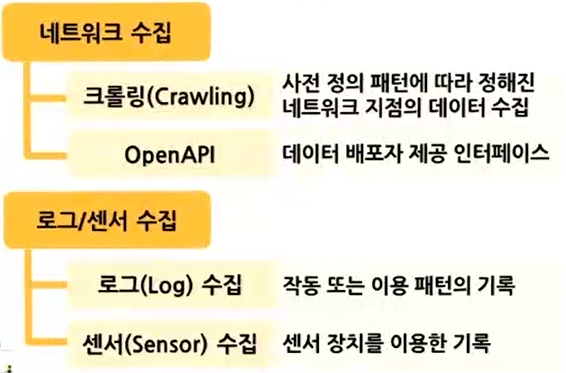
빅데이터의 자동화 수집 기술은 주로 컴퓨팅 환경에서 이루어진다. 네트워크 수집, 로그/센서를 통한 수집 등이 대표적인 예이다. 네트워크를 통하여 수집할 경우, 크롤링 또는 OpenAPI를 사용할 수 있다. 로그/센서를 통하여 수집할 경우 로그를 기록하거나 센서로부터 유입되는 값을 기록하는 형식으로 데이터 수집이 가능하다.
3. 빅데이터의 수집 사례
빅데이터는 JSON, Flume, Chukwa, SQOOP, OpenRefine, Protocol Buffers 등 다양한 수집 플랫폼과 사례를 가지고 있다.
3-1. JSON (JavaScript Object Notation)
| XML 유사 데이터 정형화 방식 |
| 인터넷 상의 데이터 송수신 방식 |
| 텍스트 형태, 작은 용량, 빠른 변환 속도 |
| 프로그래밍 언어 또는 플랫폼 독립적 |
3-2. Flume(플럼)
| 2010년 Cloudera 개발, 로그 데이터 수집기 |
| 분산 데이터 통합 가능, 안정성 가용성 높음 |
3-3. Chukwa (척와)
| 2008년 Yahoo 개발, 로그 데이터 수집기 |
| 아파치 하둡 기반, 실시간 분석 가능 |
3-4. SQOOP (스쿱)
| SQl-to-hadOOP, 다양한 DBMS 벤더 호환 |
| DBMS, 하둡, NoSQL 간 데이터 연동에 적용 |
3-5. OpenRefine (오픈 리파인)
| 2010년 Google의 오픈 프로젝트 |
| 데이터 정제 도구 : 오류 수정, 데이터 정리 |
| 데이터 연계 API 및 워크플로우 기능 제공 |
3-6. Protocol Buffers (프로토콜 버퍼)
| Google의 오픈소스 직렬화 라이브러리 |
| 다양한 플랫폼 간 통신 가능 |
'민간 자격증 > 빅데이터전문가' 카테고리의 다른 글
| 6. 빅데이터 분석 도구 R(3) (0) | 2024.07.12 |
|---|---|
| 5. 빅데이터 분석 도구 R (2) (0) | 2024.07.10 |
| 4. 빅데이터 분석 도구 R (1) (0) | 2024.07.05 |
| 3. 빅데이터 저장소 (0) | 2024.07.04 |
| 1. 빅데이터의 개념 (0) | 2024.07.01 |

댓글